¿ Peligran nuestros puestos de trabajo?
El otro día vi esta charla en la que se hablaba de la posibilidad de que en un futuro no tan lejano las personas puedan ser sustituidas por las máquinas en sus trabajos. Lo cierto es que hace tiempo que llevo pensando en esto, y es que, aunque muchas veces no nos demos cuenta, las máquinas nos están ganando terreno, por ejemplo, en muchas farmacias existen los robots para coger los medicamentos, en las fábricas muchas tareas ya son realizadas por máquinas, incluso en nuestra casa podemos ver que los aspiradores ya funcionan solos.
En mi opinión, la innovación muchas veces nos hace caer en la deshumanización, hay personas que ya no encuentran empleo porque ese trabajo está realizado por una máquina, me parece bastante triste, la verdad. Se podría pensar “que se busque otro empleo” claro, es fácil decirlo, y además teniendo en cuenta la crisis de hoy en día, no es tan sencillo encontrar empleo , y como la cosa siga así, cada vez habrá más gente desempleada. Por ello, pienso que, de cara al futuro y teniendo en cuenta que la tecnología está cada vez más desarrollada, creo que serán necesarios otros puestos de trabajo más especializados en diseñar, y producir estas máquinas, así como otros puestos dedicados a su mantenimiento. Los puestos puramente técnicos serán sustituidos a la larga por las máquinas, y exigirá por tanto la creación de nuevos puestos trabajos más especializados que antes no existían.
Lo que siempre nos diferenciará de las máquinas son las emociones, si, existen prototipos de robots capaces de sentir emociones y transmitirlas, en este campo de la inteligencia artificial se está trabajando cada vez más pero están creadas a partir de algoritmos y datos que repiten constantemente, no son capaces de crear nada nuevo, sólo son capaces de copiar y ejecutar. El cerebro humano es único e inigualable, los humanos somos capaces de pensar por nosotros mismos, y de crear nuevos pensamientos e ideas, estamos innovando continuamente en nuestras cabezas.
La innovación va unida al desarrollo de la sociedad, y en la mayoría de las veces, mejora la calidad de vida de las personas, pero debemos preguntarnos también hacía dónde va esta sociedad en la que predomina el estrés, el individualismo y por desgracia, muchas veces, el sinsentido, donde no importan los valores y la educación y lo que más se valora es el dinero. En definitiva, me estoy dando cuenta que no es necesario que vengan las máquinas para deshumanizarnos, porque en cierta parte, ya lo estamos y cada día más…
2 comentarios /
25 Nov 2016
por
Ana
 Sin categoría /
Sin categoría /
Innovación en las carreteras españolas
El otro día, mientras hacía un viaje por una autopista con el coche cruzando España, se me encendió la reserva y, buscando una estación de servicio donde parar a repostar, se me ocurrió una idea que me pareció innovadora y viene a resolver un problema que me ocurre siempre cuando viajo con el coche.
Cuando voy por la carretera y tengo que parar en una gasolinera para echar gasolina, comprar algo o descansar, la señal de tráfico que indica que en la próxima salida hay una suele ser más o menos así:

El problema es que siempre me molesta mucho no saber de antemano si la estación de servicio está a pie de carretera, en el carril contrario o en un pueblo, por lo que habría que desviarse mucho o poco, lo cual supone una pérdida de tiempo muy grande, sobre todo en viajes largos. Me encantaría tener esta información de antemano con sólo mirar el cartel y, rápidamente (estamos hablando de viajes en autopistas, con una velocidad media de 110 km/ h, con lo que tomar estas decisiones rápidamente es vital), poder tomar la decisión de tomar la salida o no. Además, si sumamos el hecho de que casi todos echamos gasolina cuando se enciende la reserva, se hace todavía más necesario saber a que distancia está la gasolinera porque, aunque la mayoría de coches tiene una reserva de bastantes kilómetros, es bastante malo para el motor recorrer muchos kilómetros en reserva y esto puede provocar ansiedad y distracción, lo cual, obviamente, es muy negativo para la conducción.
Haciendo una sencilla búsqueda por internet, he podido ver en varios foros como la gente se pregunta también si hay algún método ya existente para obtener esta información, y he podido descubrir que es bastante recurrente la molestia de tener que desviarse para echar gasolina, tema aparte serían los coches eléctricos, ya que a día de hoy no existe infraestructura para recargar las baterías, mas allá de alguna ciudad. Muchos usuarios creen haber encontrado algún patrón más o menos recurrente relacionado con la distribución de los carteles señalizadores, o con la distancia a la que anuncian la salida, pero no hay un acuerdo evidente.
Intentando encontrar normativas o reglas acerca de si existe o no esta información, no he conseguido encontrar normativa, regulación o sistema que informe de a que distancia se encuentra la próxima parada.
Así que, ante tal problema, se me ha ocurrido una solución: Utilizar un sistema de señalización por colores que identifique cuan lejos está el área de servicio de la salida. De esta manera, se propone un sistema eficaz y eficiente para poder planificar con la antelación suficiente mientras se va conduciendo por la carretera, de manera que podamos tomar la decisión de salir en la próxima salida o no.
Se usarían pues 4 colores que indicarían esta información:
- Verde: La estación de servicio está a pie de carretera, bien en el mismo carril, o bien en el contrario, pero con posibilidad de volver al carril en el que estábamos.
- Amarillo: La estación de servicio se encuentra algo alejada del carril, máximo N kilómetros, donde N es un rango que habría que definir, cómo ejemplo propongo de 1 a 5 km.
- Naranja: La estación de servicio está más alejada que el nivel amarillo, pero menos que el nivel rojo, está a un rango M de kilómetros que, igual que antes, habría que definir. Yo propongo de 5 a 10 km.
- Rojo: La estación de servicio está muy alejada de la salida e integrada en una población.
Este sistema podría aplicarse en cada cartel de las carreteras de varias maneras, bien rediseñando los carteles actuales, o bien, como solución temporal, integrar unas pegatinas que se pondrían encima de los carteles ya existentes. Esta última solución es la más económica.
Adicionalmente, podrían incluir información de la siguiente área de servicio, con el sistema de colores propuesto, de manera que si yo veo que la más próxima es amarilla, pero la siguiente es verde y está lo suficientemente cerca, podría esperar. O por el contrario, si se me ha encendido la reserva hace bastantes kilómetros y veo la distancia de la siguiente área de servicio roja, o verde pero a una distancia lejana, probablemente decidiré salir por la siguiente aunque sea amarilla o naranja, ya que estaré menos tiempo en reserva.
Enviar comentario /
23 Nov 2016
por
averastegui
Sin categoría /
¿Cuáles son los países más innovadores del mundo?
El Global Innovation Index (GII) llega a la 8ª edición con la publicación del informe correspondiente al año 2015. Se trata de una iniciativa conjunta de la Cornell University, la escuela de negocios INSEAD y la Organización Mundial de la Propiedad Intelectual (en inglés, World Intellectual Property Organization, WIPO). El núcleo del informe consiste en un ranquin de 141 economías mundiales a partir de sus recursos y resultados en el ámbito de la innovación.
El GII 2015 reconoce el papel clave de la innovación como motor del desarrollo y crecimiento económico. El informe tiene en cuenta 79 indicadores que van más allá de las medidas tradicionales de la innovación y que se pueden clasificar en 2 grandes grupos:
- Recursos: instituciones, capital humano, infraestructuras, desarrollo de los mercados y de las empresas.
- Resultados: conocimiento, tecnología y creatividad.
Según los datos del GII 2015, las 10 economías más innovadoras del mundo son, por este orden, Suiza, Reino Unido, Suecia, Finlandia, los Países Bajos, Estados Unidos de América, Singapur, Irlanda, Luxemburgo y Dinamarca. En conjunto, el grupo selecto de los 25 países punteros corresponde a economías de altos ingresos y, como en las ediciones anteriores, se mantiene bastante estable, hecho que pone de manifiesto la dificultad para alcanzar y superar los países líderes. Todo y con eso, merece la pena destacar los progresos de países como Irlanda (8ª) y la República Checa (24ª), así como los esfuerzos considerables de China (29ª) y Malasia (32ª). Por otro lado, el Estado español ocupa la 27ª posición mundial y la 18ª en el ámbito europeo.
Respecto a la calidad de la innovación, se evalúa a partir de los resultados de las universidades, la visibilidad de los artículos científicos y la dimensión internacional de las solicitudes de patentes. En este campo, las posiciones principales están ocupadas por los Estados Unidos de América y el Reino Unido, seguidos por Japón, Alemania y Suiza.
Para más información, podéis consultar la WEB del GII 2015.
2 comentarios /
16 Oct 2015
por
xcasanoves
Sin categoría /
Robots sexuales
Introducción
Recientemente estuve re-viendo un capítulo de Futurama titulado “Salí con una robot”. Futurama es una serie animada creada por Matt Groening, creador de la popular serie humorística Los Simpson. La serie sigue las aventuras de un repartidor de pizza, Philip Fry, que el 31 de diciembre de 1999 tropieza accidentalmente y cae por casualidad en una cápsula criogénica y despierta mil años después.
En el capítulo, el protagonista comienza una relación romántica con un robot con la forma de la famosa actriz Lucy Liu. A partir del momento en que esa relación se hace pública todos sus amigos (humanos y robots) se oponen totalmente a ella calificándola de antinatural. Es en ese momento en el que presentan un vídeo humorístico parodiando a los vídeos educativos de las escuelas, condenando que la gente mantenga relaciones sexuales con robots.
Incluyo el vídeo en inglés para amenizar el tema:
En las últimas décadas los avances en inteligencia artificial son increíbles: programas que participan en juegos de preguntas y que superan el test de Turing, algoritmos de visión artificial capaces de enfrentarse a imágenes como los tests de Rorschach, etc.
Añadamos a esto el desarrollo de robots humanoides en países como Japón, uno de los países con mayores avances en robótica. País dónde se han desarrollado robots capaces de tocar instrumentos, trabajar en hoteles y cuidar de personas.
Añadamos también la creación de piel sintética para prótesis que en el futuro sería indistinguible de la real.
Robots sexuales

No, no voy a hablar de las relaciones románticas que puedan establecerse entre humanos y robots, eso ya se ha tratado ampliamente en otros artículos. Además de producirse ya casos en el mundo actual, como el de Sal 9000, un nipón enamorado del personaje Nene Anegasaki del videojuego “Love Plus” con quien se casó en 2009.
La pregunta que yo me realizo tras analizar todo esto es “¿estamos tan lejos del momento en el que seres humanos y robots mantengan relaciones sexuales?”
Este tema no ha sido solamente tratado en la serie de Futurama. En la película Blade Runner se presenta un futuro en el que existen “replicantes”. Seres artificiales que imitan al ser humano en su aspecto físico y en su comportamiento, llegando a ser virtualmente indistinguibles. Estos seres artificiales se crean con diferentes modelos, entre otros obreros, soldados, comandos y trabajadores sexuales o modelos de placer. Igualmente en la película “Automata” protagonizada por Antonio Banderas aparece “un/a” robot trabajadora sexual.
¿Es por tanto esta idea tan descabellada?
El estado del arte
En el horizonte empieza a aparecer uno de los mercados posiblemente más fructíferos y rentables del futuro: el de los robots sexuales. Ahora parece una idea de Ciencia Ficción, pero ya se están sentando las bases para ello.
Un nuevo estudio titulado «Inteligencia Artificial, robótica y el futuro de los puestos de trabajo» asegura que en pocos años los robots coparán centenares de profesiones. El él se recoge la opinión de diversos expertos, la mayoría de los cuales creen que un día cercano estas máquinas desempeñarán más puestos de trabajo que en la actualidad están ocupados por seres humanos. Y gran parte de ellos no serán repetitivos empleos en cadenas de montaje sino que tendrán que ver con aspectos de la vida cotidiana, incluido el sexual.
Cada vez los robots son más parecidos a los humanos y por razones obvias, los diseñadores crean robots que deliberadamente tienen un aspecto joven y atractivo.
Un ejemplo de prototipo de robot cuya función futura puede ser el de sustituir a mujeres de carne y hueso ha sido creado en Japón y se llama Asuna.
Evidentemente Asuna no es un robot sexual pero los expertos dicen que es sólo cuestión de tiempo que este tipo de tecnología sea adaptada para tales fines. De hecho, hay empresas en Japón que ya están creando muñecas sexuales con una textura de piel tan perfecta que es “indistinguible de la real”. “Será posible mantener relaciones físicas con este tipo de androides”, sostiene Takahashi Komiyama, el portavoz de Ishiguro’s lab dónde se ha creado al robot Asuna. Una vez más Japón es una de los países más avanzados en este tema ya que cuenta con las muñecas sexuales más avanzadas del mundo, tales como las fabricadas por KanojoToys o por Orient Industry.
Por ahora, Asuna no está equipado con una inteligencia artificial avanzada o sistemas de reconocimiento de cara y voz. Sin embargo, se espera que una versión totalmente independiente se estrenará en 10 años, de la que se dice será casi idéntica a un ser humano, afirmó Takeshi Mita, CEO de a-Lab en Tokio.
Sin irnos aún de Japón, la cuestión del sexo con robots ha saltado a primer plano estos días por cuenta de Pepper, el popular humanoide doméstico que se vende desde hace tres meses y que es capaz de «leer» las emociones humanas. El fabricante, SoftBank, hace firmar a sus usuarios un acuerdo por el se comprometen a «no realizar un acto sexual o una conducta indecente con el robot».
Empresas como True Companion y Real Doll se encargan de fabricar robots destinados a usuarios que quieren tener ese tipo de relaciones sexuales, algo que probablemente irá a más y que algunos organismos quieren tratar de impedir.
En el portal studyweb.com se presenta un listado de 42 dispositivos electrónicos que existen para “tener sexo con ellos hoy“. Totalmente NSFW 😉
David Levy, autor del libro “Amor y Sexo con Robots”, dice que es inevitable que mucha gente acabe eligiendo a robots como amantes y cónyuges, ya que la tecnología está avanzando a pasos agigantados. “Yo creo que los robots sexuales serán una bendición para la sociedad”, dice. “Hay millones de personas ahí fuera que, por una u otra razón, no pueden establecer una buena relación”.
En 2015 se llevará a cabo el Segundo Congreso Internacional de “Amor y sexo con robots”. Quién esté interesado en participar puede enviar sus trabajos si están relacionados con los temas listados en su web: emociones en robots, robots clones de personas, robots de entretenimiento, enfoques afectivos a la robótica y ética en robótica.
¿Para cuando?
El sexo con robots será algo corriente para el 2050, incluso más común que el sexo entre humanos. La curiosa predicción la hace el futurólogo y matemático británico Ian Pearson, fundador de la firma Futurizon, con un 85% de exactitud en sus predicciones. David Levy anteriormente mencionado, asegura que en pocos años veremos evolucionar las versiones «crudas» que ya existen en «robots sofisticados que serán de uso común».
Según el futurista británico Ian Pearson, la evolución hacia el sexo con robots seguirán un proceso más o menos natural. En 2030 el sexo virtual en 3-D será tan ubicuo como lo es hoy por hoy la pornografía on-line. En 2035, la mayoría tendremos juguetes sexuales para interactuar con la realidad virtual. Una minoría podrá permitirse entonces el lujo de contar con robots sexuales en sus casas, hasta que se popularicen su precios y su uso.Pearson afirma además que el mercado de todo lo relacionado con el sexo será hasta siete veces mayor que hoy en día. Y el sexo con robots será posiblemente más frecuente que el sexo entre humanos.
«Mucha gente tendrá al principio reservas a mantener relaciones sexuales con un robot», admite Pearson. «Pero conforme vaya mejorando el comportamiento mecánico, la inteligencia artificial y la apariencia de las máquinas, los prejuicios se irán evaporando y la gente acabará conectando emocionalmente con los robots».
Voces a favor
Según explica el futurólogo Ian Yeoman en una conferencia en la feria australiana de Turismo recogida por el portal First To Know, las prostitutas robot podrían llegar a ser preferidas por los clientes porque evitarían el contagio de enfermedades de transmisión sexual como el VIH.
¿Parece todo esto demasiado sórdido y deshumanizado? El sexólogo estadounidense Ian Kerner ha dado una vuelta de tuerca más a este tema al sugerir que sería aceptable crear un tipo de androide ideado para que los hombres «practicasen» antes de tener sexo con una mujer y que ayudase a aquellos que padeciesen, por ejemplo, eyaculación precoz.
“Como terapeuta, no puedo sugerir en la actualidad un sustituto del sexo que sea legal. Por ello, y si hay madres de alquiler, me pregunto por qué la Inteligencia Artificial no puede ocupar ese lugar”, ha determinado Kerner.
En este sentido, el terapeuta ha señalado que, en un futuro no muy lejano, los autómatas serán un «sustituto del sexo» que ayudará a los hombres más tímidos a «practicar» antes de mantener una relación con una mujer de carne y hueso. «Crearlos permitiría a aquellos que tienen poca actividad sexual aprender a relajarse y, en un futuro, mantener relaciones con eficacia», ha destacado.
Por otro lado, Kerner planteó la posibilidad de que los «robots sexuales» podrían ayudar a determinados delincuentes. «El pedófilo es alguien con unos gustos sexuales que van en contra de los valores de la sociedad, la IA podría ser útil para que estos sujetos expresasen su sexualidad en la intimidad». En este sentido, los presentes señalaron que los autómatas podrían ser utilizados por los pedófilos de la misma forma que se utiliza metadona para tratar a los drogadictos.
Ante los diversos ataques de campañas en contra del desarrollo de estas tecnologías Douglas Hines, CEO de True Companion se defendió en los siguientes términos ”No estamos reemplazando a una esposa o tratando de sustituir a una novia». «Esta es una solución para gente que está entre dos relaciones o para alguien que ha perdido a su esposa… La gente puede encontrar la felicidad y sentirse llena de formas alternativas a la interacción humana».
Voces discordantes
Las ideas presentadas anteriormente por Kerner fueron criticadas duramente por sus colegas invitados a la mesa redonda, quienes señalaron que estos “robots sexuales! podrían causar dependencia a los nuevos jóvenes. Si hay una generación que crece con juguetes sexuales inteligentes que aprenden y tienen capacidad para satisfacer sus preferencias, podría ser que estas personas no entrasen en contacto físico con otros seres humanos”, explica en la conversación Gareth Price, graduado en IA por la Universidad de Manchester.
Dado el hecho de que la mayoría de las naciones no tienen leyes establecidas para limitar el sexo con robots y puesto que es un negocio potencial que puede ofrecer tantos beneficios, muchos expertos pronostican que las “relaciones” con androides sexuales pronto se convertirá en algo común.
Para la antropóloga Kathleen Richardson, de la Universidad de De Montfort en Leicester, estamos sin embargo en los albores de «una terrible pesadilla«. Richardson y otros expertos en ética robótica han lanzado la Campaña contra los Robots Sexuales y han reclamado a sus potenciales usuarios que «examinen sus conciencias», antes de contribuir al desarrollo de una tecnología con imprevisibles consecuencias en la vida real. En un estudio la autora expone que «las relaciones de prostitución con máquinas no son ni éticas ni seguras. El desarrollo de robots sexuales reforzará aún más las relaciones de poder que no reconocen a ambas partes como sujetos humanos».
Reflexiones éticas
En todas esas conversaciones hay cada vez una reflexión más profunda sobre la Ética Robótica y lo que nosotros mismos sentimos hacia las máquinas. Comienzan a explorarse debates por parte de gente que ama a los robots y quiere defender sus derechos, el efecto que los robots pueden causar en nosotros y sobre todo el que podrían causar si alguna vez toman conciencia de sí mismos, algo que parece aún estar muy lejos de nuestra realidad.
Todos estos debates no parecen frenar unos avances que dejan claro que hay mucho terreno por delante en todo lo relacionado con la robótica. Y desde luego también en esa rama de la robótica del placer, que a buen seguro se convertirá en una alternativa relevante para millones de personas en todo el mundo.
1 comentario /
09 Oct 2015
por
amarzo
Sin categoría /
¿Puede la ciencia ficción predecir el futuro… de la innovación?
“Los límites de lo posible sólo pueden ser definidos yendo más allá,
hacia lo imposible” Arthur A. Clarke (1917-2008)
A lo largo del máster se ha hablado mucho de la innovación tecnológica y de como ésta se sirve de la Ciencia para progresar. Pero lo que me gustaría plantear en este post es ¿puede también la ciencia ficción servir como fuente de inspiración para innovar?
En los libros y en las películas de ciencia ficción se describen sociedades que han alcanzado unos logros científicos y técnicos hipotéticos. Esto da pie a idear otros mundos muy diferentes al que conocemos actualmente, con objetos y situaciones imaginarias que no se pueden alcanzar por no existir la tecnología adecuada para ello (por lo menos, en el momento de su creación). Sin embargo, la idea está ahí y se difunde públicamente, lo que puede dar pie a investigaciones e invenciones que sí son reales. Éstas, a su vez, abren la posibilidad de imaginar una tecnología más avanzada. De esta manera, se podría decir que sí existe una relación entre la Ciencia y la ciencia ficción.
Entonces, ¿puede la ciencia ficción predecir cómo va a ser la tecnología del futuro? Vamos a ver algunos ejemplos en los que escritores y directores dan en el clavo y anticipan invenciones mucho antes de que estas se convirtieran en algo cotidiano. Al fin y al cabo, la realidad supera la ficción.

Así veían el año 2000 en el 1900
Julio Verne (1828-1905)
Julio Verne fue uno de los primeros visionarios en obras clásicas como Veinte mil leguas de viaje submarino, Viaje al centro de la Tierra, La Isla Misteriosa, De la Tierra a la Luna, entre otras.
En ellas, Verne imagina ciudades iluminadas por luces eléctricas de gran potencia, habla de un sistema de comunicación a distancia automático y secreto (similar al correo electrónico de hoy en día), de submarinos, helicópteros y trasatlánticos, de retransmisión de noticias (las primeras noticias por radio no serían retransmitidas hasta 1920) e incluso sobre viajes a la Luna, todo ello a finales del s XIX.
George Orwell (1903-1950)
Otro autor que también se anticipó a su tiempo fue George Orwell. En su obra 1984 expone un mundo que es constantemente vigilado a través de un sistema de cámaras de videovigilancia muy avanzado, diseñado por el Gobierno para controlar a los ciudadanos.

- ¿Os imagináis qué diría G. Orwell si viera hoy una edición de Gran Hermano?

JG Ballard (1930-2009)
JG Ballard describió en su ensayo de 1977 una aproximación a lo que hoy conocemos como redes sociales:
«Cada una de nuestras acciones durante el día, a lo largo de todo el espectro de la vida cotidiana, será instantáneamente grabada en video. Por la noche nos sentaremos a ver las imágenes, seleccionadas por una computadora entrenada para elegir sólo nuestros mejores perfiles, nuestros diálogos más inteligentes, nuestras expresiones más afectuosas, capturadas a través de los filtros más amables, y luego juntaremos todo ello para tener una reconstrucción mejorada de nuestro día».
Metrópolis (Fritz Lang, 1927)

- Haz click en la imagen para ver el contenido en Youtube
Metropolis es un clásico cinematográfico del género de ciencia ficción y posiblemente la primera película en la historia del cine en la que aparece un androide o robot antropomórfico. Se trata de un SER-MÁQUINA llamado “María”, que tiene la capacidad de suplantar el aspecto y el comportamiento de una persona. Son precisamente estas habilidades de transmitir sentimientos y amor los que caracterizan al personaje y por las cuales se convierte en la líder pacífica de los trabajadores.

En la actualidad, empresas como Hanson Robotics persiguen el sueño de construir androides con indicios de inteligencia y emoción humanos como Han, el robot más humano del mundo.
2001: Una odisea en el espacio (Stanley Kubrik, 1968)
La novela de Arthur C. Clarke fue desarrollada en paralelo a su versión cinematográfica y publicada poco después del estreno del film.

- Haz click en la imagen para ver el contenido en Youtube
La película anticipa las órbitas geoestacionarias y su aplicación en el campo de las telecomunicaciones, así como la inteligencia artificial gracias al superordenador HAL9000, encargado de controlar las funciones vitales de la nave Discovery.
A lo largo del viaje espacial también se puede ver cómo los personajes utilizan videoconferencias entre ellos e interactúan con pantallas táctiles.
 Como curiosidad, los abogados de Samsung no tardaron en darse cuenta del parecido que tienen estas pantallas táctiles con el actual Ipad, para utilizar la película de Kubrik como defensa en el juicio por violación de patentes entre Apple y Samsung.
Como curiosidad, los abogados de Samsung no tardaron en darse cuenta del parecido que tienen estas pantallas táctiles con el actual Ipad, para utilizar la película de Kubrik como defensa en el juicio por violación de patentes entre Apple y Samsung.
Regreso al futuro II (Robert Zemeckis, 1989)
Posiblemente todos recordemos las aventuras y desventuras de Marty Macfly en sus viajes en el tiempo gracias al entrañable Doc.
- ¿Preparados para saludar a Marty?
Concretamente en Regreso al Futuro II el protagonista viajaba a octubre de 2015, un mundo futurista con aeropatines, coches voladores y paseadores de perros. Aunque no todas las predicciones sobre el futuro se desarrollaron como Zemeckis se imaginaba en 1989, sí que dió en el clavo en otras como la videollamada o la tecnología de huellas digitales.
 Casualmente (o no), Lexus presentó este mismo año un modelo funcional del aeropatín o Hoverboard que utiliza Marty para desplazarse en la película. Podéis verlo en el siguiente enlace.
Casualmente (o no), Lexus presentó este mismo año un modelo funcional del aeropatín o Hoverboard que utiliza Marty para desplazarse en la película. Podéis verlo en el siguiente enlace.
Minority Report (Steven Spielberg, 2002)
En este caso el propio Steven Spielberg consultó cómo sería el futuro con un equipo de expertos futuristas, entre ellos científicos informáticos, filósofos, artistas y arquitectos para dirigir la película. “Quería que todos los juguetes se hicieran realidad algún día”, afirmó Spielberg en una entrevista con Roger Ebert, crítico de cine.
A lo largo de la película aparecen invenciones que se han hecho muy populares durante los últimos años, como la publicidad programática, los escáneres de retina, las interfaces multitáctiles o el software de predicción de delitos.
La trilogía Matrix (Wachowski, 1999-2003)
Seguramente recordaréis esta trilogía, mucho más reciente. En ella se representa un futuro distópico en el que lo que se percibe como realidad es una mera simulación virtual, que fue creada por máquinas sensibles al apoderarse de la población humana.

Aunque no se ha llegado al nivel de realidad virtual que se alcanza en la trilogía Matrix, actualmente ya existe la tecnología Oculus Rift que genera prácticamente la sensación de estar inmerso en otro mundo. Y sigue evolucionando.
HER (Spike Jonze, 2013)
La película tiene lugar en un futuro cercano, en el que el protagonista se enamora de un sistema operativo (Samantha) basado en el nuevo modelo de Inteligencia Artificial, diseñado para satisfacer todas sus necesidades. Durante la película, la tecnología está presente en todas partes y se activa por voz, incluyendo a la propia Samantha, su asistente personal.

Se enamoró de HER
¿Qué es real? Ya existen asistentes automáticos que se activan por voz, como Google Now y Siri, aunque evidentemente no tienen todas las capacidades que muestra Samantha en la película. Hay muchas aplicaciones móviles que a día de hoy tienen la posibilidad de funcionar a través de la voz.
Pero lo que me gustaría destacar sobre esta película es la interpretación que hace el científico y futurista Ray Kurzweil de la misma, que sostiene que el mundo será así en 2029 (podéis acceder en este enlace, eso sí está en inglés). Es más, afirma que el hecho de que Samantha no tenga cuerpo no será un problema en un futuro, sino que se podría solucionar fácilmente implantando, por ejemplo, una lente que permita proyectar imágenes en la retina.
Para los que no lo conozcan, Kurzweil es uno de los tecnólogos y especialistas en inteligencia artificial más reconocidos del mundo. Sus teorías suelen generar mucha controversia, ya que está convencido de que no habrá distinción entre máquinas y humanos dentro de pocos años.

Posthumano (haz click en la imagen para ver la entrevista a Kurzweil en Redes)
Para los escépticos sobre este tema, es muy recomendable ver la entrevista (especialmente a partir del minuto 11.40) que le hace Punset en su programa Redes, donde explica las teorías de cómo el hombre evolucionará trascendiendo la biología y se fusionará con la tecnología en un futuro no muy lejano. En otras palabras, el ser humano será capaz de desarrollar tecnologías que mejoren notablemente sus capacidades, tanto a nivel físico como biológico, para superar sus propias limitaciones humanas y llegar a controlar la propia evolución como especie. La realidad ya dejaría de existir tal y como la conocemos, convirtiendo a la especie humana en seres con extensas capacidades, merecedores de la etiqueta «posthumano«.
¿Parece increíble, verdad?
2 comentarios /
30 Sep 2015
por
mvegalopez
Sin categoría /
La robótica modular
Aunque en este blog se ha hablado mucho sobre la innovación en el mundo de la robótica, me gustaría añadir un artículo más sobre el tema, sobretodo porque muchas veces, al hablar de robótica, uno se olvida de los robots modulares, pequeños desconocidos a los que muchos solo conocen de obras de ficción.
Mucha gente, cuando piensa en los robots, piensa en ellos como una sola entidad, un solo robot con una forma específica que esta preparado para realizar un conjunto de tareas concretas. Aunque la definición es correcta, contiene uno de los mayores inconvenientes de los robots, que solo están diseñados para tareas concretas y definidas. Estas tareas pueden ser muchas y muy variadas, pero siguen siendo limitadas. Por ejemplo, un brazo robotico puede ser programado para realizar múltiples tareas, pero no puedes pedirle que haga nada que su forma le impida, como subir escaleras.
Para intentar sortear esta limitación, se pensaron los robots modulares, robots formados por robots mucho más pequeños, idénticos en forma y tamaño, que pueden cambiar de posición y combinarse entre ellos para adaptarse a cualquier situación. Todos estos robots funcionan de forma independiente a sus colegas y utilizan señales para mantener conversaciones entre ellos y saber así, desde su posición relativa dentro del robot, hasta si hay algún problema con algún robot del conjunto o la nueva forma a tomar.
Por ejemplo, es posible que los robots modulares más conocidos sean los de ficción, como el t-1000 de la película «Terminator 2», que podía cambiar su forma y color a voluntad, o los robots que utiliza el villano de la película de Disney «Big Hero 6», que al cambiar de forma permitían al usuario darles miles de aplicaciones prácticas. Si bien es cierto que la tecnología actual esta aún muy lejos de producir robots como los mencionados por limitaciones de hardware, hoy en día universidades y empresas de todo el mundo están innovando en el mundo de la robótica modular.
Los problemas a los que se enfrentan los investigadores de robots modulares son principalmente 2: la velocidad de movimiento de los robots y la vida de su fuente de energía. Algunos robots actuales pueden tardar hasta 10h en cambiar totalmente su forma y si estos son muy complejos o deben ejercer mucha fuerza, consumen enseguida su fuente de alimentación.
Aún así las ventajas de los robots modulares son enormes, imaginaos puentes capaces de cargar con el peso de camiones fabricados en minutos a partir de un par de cajas de módulos roboticos, escaleras de incendio camufladas como elementos decorativos de la fachada de un edificio que cambian de forma y se muestran como escaleras cuando detectan una emergencia, detección de personas enterradas en derrumbamientos de edificios a base de escurrirse entre los escombros o incluso se podrían arreglar robots dañados cambiando los módulos averiados por módulos nuevos. Cualquier cosa es posible siempre que se tengan a mano suficientes módulos.
Veamos algunos ejemplos:
M-BLOCK
Un ejemplo de estos módulos es el M-Block, del MIT. Cubos que son capaces de conectarse entre si y de moverse de forma independiente mediante saltos calculados (sí, los cubos saltan, literalmente) para aterrizar en su posición decidida por el el conjunto de módulos.
KILOBOTS
Los Kilobots, de la Universidad de Harvard, son pequeños robots con sensores infrarojos capaces de formar cualquier figura conexa a base de moverse por el perímetro del conjunto de Kilobots y de detenerse en la posición que les corresponde.
MTRAN3
Por último me gustaría mostrar uno de mis favoritos, el MTRAN3, de AIST y Tokyo-Tech fabricado en 1998. Estos módulos son como juntas o bisagras conectadas por sus extremos y equipadas con sensores para detectar colisiones que permiten, cambiando la forma del robot, arrastrase como una serpiente, caminar como una araña o incluso a cuatro patas, pudiendo sortear problemas como escalones de diferentes tamaños.
El futuro de los robots modulares
Lamentablemente las limitaciones del hardware, tanto por el tamaño de los elementos necesarios como por su potencia y su consumo de energía, han dejado la investigación con robots modulares relegada a un segundo plano hasta que se encuentren soluciones viables. A penas un pequeño puñado de empresas y universidades siguen investigando en este campo tan interesante a nivel teórico, como el caso de NASA, o realizando pequeñas demostraciones con robots de diferentes formas y tamaños capaces de realizar tareas de cambio de forma.
Aún así, una vez pasada esa barrera, se esperan grandes cosas de la robótica modular y de sus posibles aplicaciones tanto en empresas como en el día a día.
Enviar comentario /
28 Sep 2015
por
mperea
Sin categoría /
MACHINE LEARNING
Sería allá por el año 2002 cuando por primera vez formé parte de un equipo de I+D aplicada, cosa que no se ha vuelto a repetir hasta ahora y difícilmente creo que se vuelva a dar. Como soy licenciado en informática, obviamente, mi campo era la I.A. En concreto nos centrábamos (si es que se puede decir que estábamos centrados en algo) en los siguientes campos:

- Representación del Conocimiento
- Sistemas expertos
- Redes neuronales
- Árboles de toma de decisiones
- Programación declarativa
Sí compañeros, como podéis ver le dábamos a casi todo por aquel entonces. Digamos que aquello era una “rave” del procesamiento computacional. La cosa que más me chocó de todo, fueron los sistemas expertos y las redes neuronales, por la capacidad de aprender que tienen. Uno de estos sistemas es capaz de tomar decisiones a través del aprendizaje y que resulta relativamente sencillo de implementar eran los sistemas expertos, en los cuales, simplemente tenías que definir un conjunto de probable de entrada y darle una salida correcta.
Obviamente, a medida que el sistema empieza a aprender, comete muchos errores en función de que la muestra de “entradas conocidas” sea más o menos amplia y de que su distribución sea uniforme a lo largo de la población muestreada. Una vez que vamos corrigiendo errores en la salida, el proceso va almacenando dicho conocimiento, añadiéndole un peso a cada condición de entrada respecto a la salida esperada. Una vez que crece el conocimiento heurístico que el sistema es capaz de almacenar, es capaz de anticipar salidas desconocidas según el escenario de entrada.
Me hacía gracia pensar que un sistema experto está un poco vivo, en tanto en cuanto tenía que aprender y que cuanto más tiempo dedicábamos a enseñarle más rápido aprendía y mejor lo hacía… tal y como una mascota o un ser humano. Pero lo que sucede en realidad no es algo tan mágico, es mucho más simple, una inferencia estadística según un escenario inicial y una salida con una probabilidad de éxito.
Recientemente me he vuelto a topar con esta rama de la I.A., concretamente con el machine learning y me he acordado de lo que hacía y así he podido comparar cómo han avanzado los algoritmos computacionales.
Estamos en la era de los datos, sólo que los datos que se tratan ahora son datos no estructurados. Son Terabytes de información que se obtienen de distintos orígenes, el mundo de la integración de sistemas y estaba claro que para explotar dicha información necesitábamos dotar al hardware de un mecanismo para ello. Es aquí donde el machine learning toma importancia, ya que es capaz de inferir información concreta sobre una base de información sin estructurar, o lo que es lo mismo, es capaz de inducir conocimiento de, por ejemplo, textos descriptivos.
Esto sirve para cosas tan complejas como clasificar comportamientos o características y como podéis imaginar la aplicación es la que quieras dar al resultado de dicha información, desde sectorizar o predecir comportamientos ya sean de personas u otro tipo de entidades que nos proporcionan información.

Nosotros, en concreto, nos centramos en la sectorización empresarial por la actividad desarrollada según descripciones obtenidas por distintos medios. De esta forma, nos hemos decantado por algoritmos de máquinas de vectores de soporte (SVM) y por clustering.
Son los algoritmos SVM los que mejores resultados nos han proporcionado en la clasificación y su funcionamiento es muy sencillo. De momento sólo estamos utilizando esta técnica para deducir a qué sector pertenece una empresa. Como los sectores empresariales se solapan (la misma empresa puede estar en dos sectores al mismo tiempo), no podemos crear un único modelo, sino que debemos crear un modelo por cada sector y aplicárselo a todas las empresas.
Para ello cogemos un sector determinado y un conjunto de entrenamiento formado por empresas que pertenecen al sector, cuanto mayor sea el conjunto de entrenamiento mejores resultados nos dará el algoritmo, pero también podemos suministrar en nuestro conjunto de entrenamiento empresas que no pertenecen al sector, ya que también el sistema aprende de los casos negativos. Nos está dando muy buenos resultados y una vez generados los diccionarios es realmente rápido. Para que entendáis mejor cómo se realiza la vectorización de un texto os pongo el siguiente ejemplo:
- texto1: “La casa verde”
- texto2: “El perro de la casa
Construimos primero nuestro diccionario:
la => 1, casa => 2, verde => 3, el => 4, perro => 5, de => 6
Hemos construido un diccionario de 6 dimensiones. Ahora podemos vectorizar los textos, donde cada dimensión corresponde a una palabra del diccionario:
- texto1 => (1, 1, 1, 0, 0, 0)
- texto2 => (1, 1, 0, 1, 1, 1)
Para obtener mejores resultados, se pasa toda el texto a minúsculas, se quitan tildes y caracteres especiales, se eliminan las stopwords (palabras más comunes del idioma, en nuestro ejemplo serían: la, el, de) se lematizan todas las palabras (eliminando plurales, declinaciones, conjugación de verbos, etc.) y se utilizan bigrams o trigrams (conjuntos de 2 o 3 palabras seguidas).
Obviamente un algoritmo de extracción de keywords (palabras clave sobre la información de una entidad concreta) nos permitiría tener un diccionario mucho menor y así obtener mucho mejores resultados a la hora de aplicar el algoritmo SVM, que es en lo que ahora estamos trabajando.
También estamos intentando afinar un algoritmos de clustering que nos permita extraer agrupaciones de la población de entidades que manejamos, para obtener automáticamente los sectores sugeridos por el sistema.
De este modo entre unos y otros algoritmos podemos llegar a tener unos resultados muy eficientes.
Es ahora cuando asusta ver que una máquina puede aprender mucho más rápido que nosotros y dar mejores resultados, lo que me tranquiliza al final es que por mucho que aprenda, jamás entenderá la información de una manera lógica y por mucho que sea capaz de deducir, inducir o reducir, no se dejará llevar por la intuición ni tomará conciencia de sus actos o existencia, vamos que la era de Skynet aún se me antoja lejana…

Bibliografía
Para desarrollar esto me he apoyado en algunas entradas de la Wikipedia, pero sobre todo os he buscado enlaces de interés para que podáis ahondar más en un tema que considero realmente apasionante:
- Representación del Conocimiento https://es.wikipedia.org/wiki/Representación_del_conocimiento
- Sistemas Expertos https://es.wikipedia.org/wiki/Sistema_experto
- Redes Neuronales https://es.wikipedia.org/wiki/Red_neuronal_artificial
- Árboles de toma de decisiones https://es.wikipedia.org/Árbol_de_decisión
- Programación declarativa https://es.wikipedia.org/wiki/Programaci%C3%B3n_declarativa
- Machine Learning https://es.wikipedia.org/wiki/Aprendizaje_automático
- SVM https://es.wikipedia.org/wiki/Máquinas_de_vectores_de_soporte
- Extracción de keywords https://www.airpair.com/nlp/keyword-extraction-tutorial
- Clustering https://es.wikipedia.org/wiki/Algoritmo_de_agrupamiento
5 comentarios /
25 Sep 2015
por
acarcedo
Sin categoría /
LIDERAR EN TIEMPOS REVUELTOS
LIDERAR EN TIEMPOS REVUELTOS
Francesc Vineglas
Una de las cuestiones básicas por no decir trascendentales que creo que deben darse en el proceso de innovación es un buen lideraje, hasta el punto estoy convencido de esta afirmación que sin líder no hay innovación, el talento requiere de alguien que sepa localizarlo, gestionarlo y enfocarlo a una finalidad concreta y especifica, sino se pierde.
Siempre se ha tenido una visión del lideraje muy psicológica, centrada en características y aptitudes innatas materializándose en personas de carácter y capacidades extraordinarias que con sus iniciativas y ejemplo han conducido a los demás por los derroteros del
beneficio común, no voy a ser yo quien desmienta esta visión del lideraje como monopolio de ciertos individuos para ver mas allá, dirigir de manera más efectiva o canalizar los deseos y esperanzas, sin embargo, sin olvidar que hay parte de razón en el planteamiento anterior pienso que liderar es cuestión de oportunidad y conocimiento y bajo este ángulo se puede aprender a liderar, es como si la psicología nos hubiera enseñado que hay hombres extraordinarios pero por otra parte y desarrollando ya conceptos de la Ilustración que somos muy parecidos, y bajo esa premisa objeto de estudio y a partir de ahí nace este concepto de aprendizaje de unas habilidades para conseguir un objetivos, en este caso liderar.
Aquí os dejo un cuestionario para evaluar vuestras capacidades para liderar y ver que os sobra o falta para conseguir ser un buen líder.
How Good Are Your Management Skills?
Hacer click en el enlace http://www.mindtools.com/pages/article/newTMM_28.htm
para abrir el recurso
Enviar comentario /
21 Sep 2015
por
fvineglas
Sin categoría /
Ética e Innovación
En los últimos tiempos, igual que en este curso, la innovación esta en boca de todos. Todos hablan de innovación y emprendeduría como una manera de salir de la crisis, como una manera de generar nuevos valores que permitan a las empresas ser más competitivas y en general con multitud de calificativos positivos. La mayoría vemos la innovación como la panacea para muchos de los problemas. A menudo, sin embargo, parecemos olvidar las repercusiones que pueden tener las innovaciones en la vida de las personas, en la sociedad. Y uso el término repercusiones sin pretender asignar el calificativo despectivo que en ocasiones se asocia con esta palabra. Lo hago de esta manera para intentar mostrar que, aunque al hablar de innovación pocas veces se habla de ética, quizás el innovar deba conllevar una evaluación de las repercusiones que dicha innovación puede tener sobre la sociedad.
Así pues, se plantean las siguientes preguntas: ¿Porque es necesaria la ética en la innovación? ¿Debe la ética parar el progreso? Por supuesto no se trata de preguntas fáciles de responder, pero día a día llegan a nuestros oídos dilemas éticos relacionados con la innovación y es a posteriori cuando llegan estas preguntas. ¿Podría se quizas interesante unir la reflexión ética a la innovación?
Entendemos la ética como la rama de la filosofía que estudia el bien y el mal y sus relaciones con el comportamiento humano, con la moral. Una definición semejante de la ética pudiera parecer que no tiene cabida en el mundo actual, donde los conceptos de valor o desvalor quedan diluidos entre principios religiosos, políticos, sociales y económicos. Sin embargo, el sentido ético se podría presentar de forma simple entre el valor de beneficio y el desvalor de perjuicio para la sociedad y las personas. Por supuesto, dado que nada es blanco o negro, ninguna de estas evaluaciones se ofrece sencilla. Y dado que nada es neutro, es difícil alcanzar este valor o desvalor sin considerar los intereses en juego y la influencia que éstos puedan tener en este resultado final del beneficio/perjuicio.
A título de ejemplo, a todos han llegado noticias del cambio climático y las medidas recomendadas a fin de detenerlo. Encontramos noticias como las que se muestran en el siguiente link:
http://elpais.com/elpais/2015/09/11/ciencia/1441978325_897742.html
Esta noticia ofrece una medida para combatir el cambio climático si los líderes mundiales no son capaces de llegar a un acuerdo. Sin embargo, desconocemos que repercusiones reales pueden tener estas sombrillas sobre el ecosistema completo del plantea tierra. Atreviéndonos a ir todavía un poco más lejos: ¿no hubiese sido mejor llevar a cabo una evolución, una innovación, sostenible en lugar de llegar a este punto de casi no retorno? Aún más, ¿no hemos aprendido nada de la trayectoria que nos ha llevado al estado actual? Es decir, si hasta ahora la evolución tecnológica, realizada sin evaluar detenidamente las consecuencias, nos ha conducido a un punto en el que es necesario instalar sombrillas solares, quizás sería recomendable evaluar las implicaciones éticas de colocar este par de sombrillas a modo preventivo.
Por supuesto las innovaciones tecnológicas no alcanzan únicamente al sector energético o medioambiental. En los últimos años venimos contemplando una intromisión cada vez mayor en la vida personal de todos los individuos. Sin embargo, en el momento en el que aparecieron las innovaciones de las redes sociales y del Internet de las cosas, no se plantearon los problemas que ahora empiezan a aparecer. Una reflexión a tiempo sobre estos problemas quizás no hubiese evitado llegar a los extremos presentes puesto que en estos casos el bien que proporcionan las redes sociales parece superar sus efectos adversos. Por otro lado, sí que hubiese permitido estar más preparados para afrontar los problemas que más tarde han aparecido y para algunos de los cuales se ha legislado rápida e ineficientemente:
http://www.abc.es/tecnologia/noticias/20150615/abci-derecho-olvido-201506151117.html
http://abcblogs.abc.es/ley-red/public/post/el-desordenado-panorama-del-derecho-al-olvido-15932.asp/
http://politica.elpais.com/politica/2015/01/23/actualidad/1422015745_590889.html
Queda claro que al hablar de innovación no hablamos únicamente de nuevos productos. En otros campos podemos encontrar ejemplos de “innovación” caso de:
Parece curioso encontrar noticias como estas en un mundo en el que se lucha por la igualdad entre mujeres y hombres, así como por la dignidad de las personas. La dignidad de los individuos es, sin duda, uno de los puntales que debe evaluarse desde la perspectiva ética para decidir si un proyecto debe o no seguir adelante.
Habrá quien defienda que si una innovación no supone un beneficio para la sociedad esta no va a ser aceptada. A no muchos años vista tenemos el caso de las gafas de google y todos los problemas que plantearon. Al final parece que su salida al mercado se demoró y que provocó muchas polémicas como la que se muestra:
http://tecnologia.elpais.com/tecnologia/2014/01/21/actualidad/1390299676_075132.html
En este caso la polémica se encendió antes de que las gafas llegaran al gran público, sin embargo no pasa lo mismo con otras innovaciones. La pregunta que deberíamos plantearnos entonces es: ¿Todo vale cuando hablamos de innovación? Quizás deberíamos hacer un esfuerzo por vincular la innovación de empresas, instituciones y particulares, por vincular la ética a los proyectos de innovación.
Resulta exigible que la ética obligue a aplicar un principio de prevención y precaución apriorístico a toda posible innovación.
El principio de prevención o precaución se evalúa por factores previos sencillos que obligan a entrar a la ética, como al valor superior de la dignidad de la persona. El primer principio es que los principios de prevención o precaución atienden a una ecuación sencilla, el progreso y los avances tecnológicos tienen como destinatario a las personas, y en tal ecuación las personas no son el objeto o conejillo de indias de tales avances, sino el sujeto, la piedra angular. Los avances pretenden su beneficio en todos los sentidos, dentro del respeto de tal valor central, respeto a su vida, a su integridad física y psíquica, pero también a su intimidad y a su propia libertad decisión.
Por tanto, la exigencia de prevención o precaución parte de la premisa de que el avance tecnológico no puede comportar un riesgo no asumible por estos valores de la persona. Y para saber el nivel de riesgo y su afectación a estos valores, lo primero exigible es el propio conocimiento del riesgo existente, el grado o nivel de riesgo que conlleva. El avance tecnológico debe ser capaz de generar suficiente conocimiento de sí mismo, de tal modo que se pueda evaluar su nivel de riesgo en el entorno y en la realidad de las personas e incluso otros seres vivos y bienes relevantes.
En la medida que los avances tecnológicos no cumplen tales premisas entra en juego la ética y la dignidad de la persona. El desconocimiento de riesgo y su afectación sobre la persona y el resto de seres vivos hace que se estos se conviertan en instrumentos y objetos de evaluación del riesgo. Los convierte en instrumento, conejillos de indias, puesto que serán los que sufrirán tales consecuencias y los que darán a conocer el nivel de riesgo padecido, sufrido por dicha injerencia tecnológica.
Y esto dará lugar a que a la hora de evaluar el bien representando por la persona y el resto de seres vivos, o el bien representado por el propio avance tecnológico, predomine éste último.
http://blog.inerciadigital.com/2013/06/25/vertederos-tecnologicos/
Día a día nos encontramos con problemas relacionados con la tecnología y con los avances tecnológicos. La innovación se ha convertido en una parte muy importante de la sociedad en la que vivimos. Si aceptamos esto como cierto, deberíamos aceptar también que es importante entender qué repercusiones va a suponer una innovación para la sociedad. Es aquí donde se puede llegar a la conclusión de que la ética es importante para la innovación. A la pregunta de si la ética debe parar la innovación no daré respuesta, lo dejo a la opinión del que lea esto. Lo único que planteo es que detenga o no la innovación, una reflexión sobre la implicaciones, positivas o negativas, de un proyecto innovador, podrían permitir que la sociedad estuviese mejor preparada para aceptar los cambios que se avecinan.
Terminando, si los ejemplos expuestos, los diversos argumentos o el sentido común no fuesen suficientes para apoyar la tesis de que la ética debe ir unida a la innovación, la comisión europea, tiene en cuenta estos aspectos a la hora de definir sus planes de investigación y desarrollo y a la hora de definir los planes de ayuda como Horizonte2020.
http://sociedad.elpais.com/sociedad/2013/04/30/actualidad/1367342938_884354.html
Así pues, parece que la política ya esta tomando las primeras medidas relativas a este aspecto, ¿creéis que las empresas comparten este punto de vista?
1 comentario /
20 Sep 2015
por
dezquerra
Sin categoría /
Nuestros Smartphones
Tal y como viene siendo habitual en mis artículos de debate en Linkedin el tema de esta entrada trata sobre el mundo de la tecnología móvil, en una breve introducción de cómo los móviles han cambiado nuestra vida, para posteriormente explicar a qué podremos optar en un futuro próximo con nuestro teléfono así como los usos actuales que también tienen y que resultan sorprendentes o curiosos.
Así pues, a día de hoy es normal la imagen de un grupo de personas o amigos mirando sus móviles sin levantar la vista, ir en el metro sin saber quién está a tu alrededor, hay muchos ejemplos. El caso es que se ha convertido en un instrumento que influye en nuestra manera de relacionarnos con los demás, ya sea amigos, familia, pareja o conocidos.
Lo cierto es que esta adicción está totalmente ligada al impacto que ha supuesto esta tecnología en la sociedad y al emergente crecimiento de las apps para móviles ha cambiado la forma de hacer muchas tareas diarias como por ejemplo comprar o simplemente leer las noticias.
Todo este efecto ha provocado que muchas empresas hayan decidido sacar productos (con mayor o menos éxito) que ayudan a la gente a desintoxicarse propiamente de su smrtphone. Como ya hemos visto en otros artículos que he compartido en Linkedin, desde la famosa empresa australiana que desarrolla un pimentero que apaga los dispositivos móviles en la mesa, hoteles que ofrecen dejar su móvil bajo llave hasta el término de sus vacaciones, aplicaciones que miden tu grado de adicción al móvil o los carriles peatonales para personas que van por la calle utilizándolo.

Por otro lado, la futura llegada de la tecnología 5G asegura unas comunicaciones tan rápidas que permitirán ampliar notablemente el uso del teléfono a otros aspectos de la vida diaria y también el desarrollo real del llamado Internet de las Cosas. Por ejemplo la posibilidad de informar a través del móvil de accidentes de tráfico, atascos, estado de las infraestructuras mediante multitud de sensores conectados, posibilidad de descargar películas en tu teléfono, manejar máquinas a distancia, en definitiva, multitud de nuevas posibilidades al poder reducir el tiempo que tarda la información en llegar de un lugar a otro. Aquí tenemos algunos ejemplos más.
Sin embargo, a pesar de todo esto, que llegará en un futuro próximo, actualmente un smartphone nos ofrece muchas posibilidades: realmente lo sorprendente viene cuando uno descubre la gran variedad de aspectos en los que un teléfono inteligente puede ser de utilidad, casi siempre solamente mediante las apps que puedes instalar o en otras ocasiones en asociación con otros aparatos.
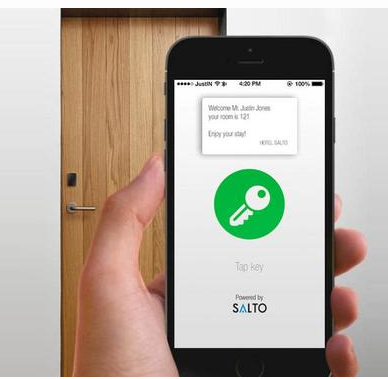
De hecho, aunque antes hayamos visto que hay hoteles que nos dan la posibilidad de desconectar de nuestra tecnología móvil durante las vacaciones, abrir la propia habitación de un hotel con el teléfono móvil ya es posible La compañía española Salto System ha desarrollado la tecnología necesaria tanto en la parte de la cerradura de la puerta como la app necesaria para ello, gestionando esta comunicación bien mediante Bluetooth o bien mediante NFC y almacenando la información necesaria con un cifrado de datos. Aunque todavía no es algo que esté totalmente extendido la empresa está instalando actualmente esta tecnología.
Más sorprendente resulta el uso del smartphone en el ámbito de la medicina. Así mismo, un móvil con microscopio es capaz de detectar parásitos en la sangre. Un equipo de científicos de la Universidad de Berkeley ha desarrollado una nueva herramienta denominada como “CellScope” que se incorpora en un teléfono móvil y mediante vídeo detecta y cuantifica automáticamente (en un lapso de dos minutos) de qué infección parasitaria se trata utilizando únicamente una gota de sangre. Este estudio, que ha sido publicado en la revista Science Translational Medicine, detalla que el dispositivo mueve la muestra de sangre delante de la cámara del teléfono y un algoritmo analiza de forma automática el movimiento de los gusanos. Unos minutos después, se visualiza en la pantalla el recuento de los gusanos y su tipología.

Siguiendo con el uso del smartphone en el ámbito médico, un grupo de ingenieros de la Universidad de Columbia (EE.UU.) ha conseguido simplificar la costosa prueba para detectar la presencia del virus del sida o de la bacteria sífilis en nuestra sangre. Todo se ha reducido a un simple pinchazo en el dedo, un pequeño dispositivo con un coste de menos de 30 euros y un smartphone. Su funcionamiento es muy sencillo: obteniendo la sangre el pinchazo, se deposita la muestra en el accesorio que se conecta al smartphone realizando un triple test de anticuerpos, los del VIH, los específicos para la sífilis y otros utilizados para detectar esta infección bacteriana. El resultado puede obtenerse en 15 minutos.

Desde esta manera, con estos avances que hemos visto, los diagnósticos de laboratorio se pueden hacer accesibles para casi cualquier población con acceso a un teléfono inteligente.
Otro invento con bastantes aplicaciones para el futuro es el de un grupo de investigadores del Instituto Tecnológico de Massachusetts han ideado un pequeño dispositivo portátil que se coloca sobre el pulgar y que lo convierte en un dispositivo de control inalámbrico con la idea de que el usuario pueda manejar de este modo distintos aparatos y con capacidad para programar distintos patrones de movimiento. El prototipo, que se llama «NailO», permitirá por ejemplo enviar un mensaje a través del teléfono o navegar entre varias aplicaciones o pantallas mientras estás cocinando o hablando por teléfono.

Incluso la marca de cosmética L’Oréal Paris ha presentado una tecnología que permite el reconocimiento facial en movimiento. Esta app consigue que los usuarios prueben los productos de maquillaje en tiempo real y en movimiento mirándose al espejo de realidad virtual de su móvil o tableta. La herramienta se basa en un algoritmo obtenido tras el análisis de miles de rostros de distintas etnias. En esencia, funciona con un mapeo facial que capta 64 puntos de la cara y 100 expresiones faciales distintas. Para desarrollar esta aplicación, que cabe destacar que se encuentra en el top 5 de descargas en EEUU), L’Oréal ha colaborado con una empresa especializada en el reconocimiento facial. Una tecnología similar ha sido empleada en la película “El Curioso Caso de Benjamin Button” o en el famoso videojuego “Grand Theft Auto V” para conseguir rostros más reales.

Por último, y a modo de curiosidad, nuestro teléfono ya nos da hasta la posibilidad de colaborar con proyectos científicos: “Science in your Mobile” es una app desarrollada por la fundación Ibercivis y la Universidad de Zaragoza que permite a sus usuarios colaborar en la investigación de varios proyectos científicos que presenta al usuario en forma de juego.
Otra aplicación muy parecida es “Samsung Power Sleep”. Si nos descargamos esta app para Android, cuando no estemos usando el teléfono, este será utilizado para procesar datos obtenidos de experimentos, por lo que cuanta más gente se sume a esta iniciativa, menos tiempo se tardará en dar sentido a todos esos datos que se obtienen a diario. Aquí podéis ver el vídeo.
En definitiva, con todo esto queda demostrado el importante papel que juega actualmente nuestro teléfono móvil en la vida diaria y también su presencia en los proyectos de innovación que se realizan en diferentes sectores.
1 comentario /
08 Sep 2015
por
jmartinezdiaz
Sin categoría /
Metodología para evaluación de convocatorias de ayuda a la I+D+i
¿Cuántas veces hemos oído que la I+D+i tiene que estar apoyada desde la alta dirección de la empresa? ¿Cuántas convocatorias de ayudas con bases de cientos de páginas hay disponibles?
Una de las labores principales de un Tecnólogo es identificar a qué convocatoria convocatoria de ayudas presentarse y exponer a la dirección los motivos que han llevado a tal decisión para obtener la necesaria esponsorización. Esta entrada pretende identificar los puntos principales que permitan comunicar nuestras razones en un documento de no más de una página o en una exposición de no más de 5 minutos.
No se pretende realizar un análisis detallado de la convocatoria ni mucho menos decidir la participación definitiva en la convocatoria sino pasar un primer filtro y poder responder a la pregunta ¿merece la pena invertir un minuto más en esta convocatoria?
He identificado tres áreas principales a revisar cada una de ellas con varios campos según el esquema que se muestra a continuación:
 1. Introducción a la convocatoria:
1. Introducción a la convocatoria:
- Nombre y tipo de ayuda (Pública Europea, Pública Nacional, Pública Regional o Privada)
- Información de la convocatoria: Contacto, web, etc
- Breve descripción de la convocatoria
- Documentación de referencia

2. Encaje con la convocatoria:
- Lugar, fecha y descripción de la documentación a presentar
- Tecnología de la empresa aplicable
- Beneficiario de la ayuda: Empresa individual, consorcio, otros
- Duración del proyecto
- Encaje con topic, alcance e impacto esperado
- Criterios de evaluación de la convocatoria
- Posibilidad obtención ayuda
- Incompatibilidad con otras ayudas. Requisitos de la empresa

 3. Evaluación preliminar de recursos y financiera
3. Evaluación preliminar de recursos y financiera
- Modalidad de financiación: Préstamo, subvención, beneficios fiscales, etc… y sus condiciones. Presupuesto mínimo y/o máximo
- Resultado de la evaluación económica preliminar. Evaluación económica en página aparte
-
Estimación RRHH necesarios para realizar el proyecto y preparar la oferta
De todos los campos que se muestran en el esquema quiero llamar vuestra atención sobre algunos de ellos:
- Breve descripción de la convocatoria: Uno de los primeros consejos que recibí, y que recuerdo constantemente, al empezar a trabajar con normativa es: «Lo más importante de una Norma es el título». Las convocatorias tienen bases de cientos y cientos de páginas, esta extensión e información masiva no debe hacernos nunca perder la orientación que proporciona el título de convocatoria. En este punto yo suelo indicar el título de la convocatoria incluyendo alguna breve explicación en caso que la terminología empleada no sea familiar para el lector.
- Encaje con topic, alcance e impacto esperado: Este es, mi opinión, el punto clave. Si nuestra idea o producto no encaja con los objetivos, alcance e impacto esperados por la convocatoria no merece la pena presentarse. En caso de no tener un buen encaje y justificación no hace falta dedicar ni un segundo más al estudio. Si hay dudas se puede consultar, para proyectos europeos o o similares se puede contar con la ayuda del personal del CDTI. Esta consulta a especialistas sería un «MUST» en caso que se deciera proceder con la presentación a la convocatoria.
- Incompatibilidad con otras ayudas. Requisitos de la empresa: Filtro Si-No generalmente fácil de verificar y puramente objetivo. Esta características hacen que este aspecto sea fundamental y uno de los principales motivos para que nos tiren por tierra nuestra perfecta respuesta a cualquier otro requisito de la convocatoria.
- Resultado de la evaluación económica preliminar: No se pretende realizar un estudio pormenorizado simplemente un resumen de cómo serían los «números gordos» del proyecto. No creo que se pueda conseguir una apoyo de la dirección sin un balance positivo y creíble aunque preliminar del proyecto.
- Estimación RRHH necesarios para realizar el proyecto y preparar la oferta: En el presupuesto se deben haber identificado los recursos humanos necesarios para la realización del proyecto para valorar el coste de los mismos. Quisiera remarcar aquí, la no menos importante capacidad y la planificación necesaria para preparar la documentación necesaria. Ya se que es difícil, pero de las estadísticas de entrega de documentación se desprende que todo se hace en el último momento y espero estéis de acuerdo conmigo en que las prisas no son buenas.
Al final de la ficha recomiendo incluir una línea resumen de la evaluación del departamento de I+D+i y otra en la que se refleje la decisión final de la empresa para futuras referencias. Estas fichas pueden formar parte del registro de Vigilancia Tecnológica de vuestra empresa de acuerdo a lo requerido por la norma UNE 166002.

Espero que esta guía pueda servir a alguien en su trabajo diario y, por supuesto, os invito a todos a compartir vuestras experiencias y a incluir cualquier comentario o reflexión.
Enviar comentario /
07 Sep 2015
por
vruizmartinez
Sin categoría /
Innovación en la forma de adaptarse
Hace años cayó en mis manos un libro que cambió mi manera de ver el proceso de desarrollo del software y, en general, cualquier proceso de construcción de algo, incluso vital. El libro era «UML y patrones» de Craig Larman y me proporcionó una visión (creo que) muy acertada sobre cómo enfocar la construcción de algo: paso a paso, adaptándose al cambio y siempre buscando soluciones.
Donde dije digo…
Esto es lo primero que debemos asumir, el cambio. Da igual que te estén contruyendo un complejo sistema software que sirviendo una ración de calamares. Algo no te va a gustar y vas a querer cambios. Esto es una condición inherente al ser humano y a la comunicación. No es posible comunicar el 100% de lo que queremos comunicar. Por ponerlo simple, entre la cabeza del emisor, el método de comunicación (verbal, chat, email…) los ojos u oídos del receptor y su cabeza, hay un montón de puntos donde el mensaje se corrompe. Para evitar esos saltos en el entendimiento, es aconsejable seguir algunas buenas prácticas.

Algunas pistas para reducir los cambios
En definitiva, el cambio llegará, por muchos esfuerzos que hagas, así que prepárate para afrontarlo.
Gestión de la espectativa
Muy relacionado con lo anterior. Si pediste una ración de calamares y el camarero te dijo que «es una ración grande» y luego te trae un plato con 3 calamares, es probable que tu decepción se vea incrementada con buenas dosis de cabreo (legítimo cabreo, eso sí). Y es que para que un cliente, un amigo, un compañero de trabajo, en definitiva, alguien que espera algo de tí se vea razonablemente satisfecho, es necesario gestionar correctamente aquello que espera. En este punto, en el mundo empresarial, especialmente en el de las consultoras, surge el eterno conflicto entre marketing y realidad. Marketing suele prometer más de lo que la realidad puede dar y de ahí muchas de las decepciones.
Under promise, over deliver
O dar un poco más de lo que espera el cliente. Ojo, no confundir con sobreestimar. Se trata de prometer algo factible y aunque la entrega se retrase, añadir algún valor a dicha entrega para que la sensación sea mejor.

Dar más de lo que el cliente espera es una buena manera de mantenerle contento
Hace unas semanas encargué por Internet comida para mi perra. Al dia siguiente recibí un email diciéndome que se habían quedado sin existencias, que tardarían 2 días más, pidiéndome mil disculpas por ello. Como no tenía urgencia, no me importó, así que no cancelé el pedido. Cuando llegó, junto al pienso, me habían incluido unas cuantas golosinas que mi perra agradeció mucho. Detalles que hacen que la promesa incumplida no sea tan dolorosa y evitan la pérdida de un cliente. Incluso fideliza. Los restaurantes llevan toda la vida haciéndolo con los chupitos tras la cuenta.
Nobody cares about the thing you’ve designed, unless you can get them past the beginning.
https://medium.com/the-year-of-the-looking-glass/design-the-beginning-b8e61081ce42
En este artículo se habla sobre la importancia de la primera impresión que causa en el cliente la presentación de un nuevo producto. Es algo clave despertar ese interés inicial para que haya siguientes pasos en la comunicación que permitan concretar una venta. Algunas preguntas que debe hacerse un buen vendedor:
- ¿Dónde y cómo será la primera comunicación sobre el producto con el cliente? Es importante que el lugar sea adecuado, que sea tranquilo y agradable y permita centrar la atención de a quien dirigimos la exposición.
- ¿Cuáles son los puntos clave a dar a conocer? Deben estar claros y fácilmente entendibles y seguibles.
- ¿Qué es lo que verán en el primer minuto? ¿Cómo planeas hacer la demostración? Como pierdas la atención pronto, no habrá ya forma de arreglarlo.
- ¿Cómo será la expansión social del producto? Es importante diseñar el grafo social antes de que éste se cree sin control. Para ello es útil elegir buenos #hashtags, dominios, slogans, etc.
- ¿Qué es lo que hará volver a tus clientes una segunda o tercera vez? Este punto sea quizá el más importante porque es la clave de que todo lo anterior haya servido de algo.
Satisfacción, UX y feedback
Hay multitud de aspectos relacionados con la satisfacción del cliente, pero creo que centrarse en el comienzo de la experiencia de usuario puede ser la clave del éxito. Ahí tenemos los ejemplos de Apple y sus productos que, a pesar de ser notablemente más caros, siguen vendiendo muchísimo debido a la satisfactoria experiencia de uso de sus clientes.
Por último, el feedback o retroalimentación es básico para poder reconducir el producto hacia lo que realmente necesita o desea el cliente. Es conocido el artículo del modo en que contruye Spotify sus productos (https://dl.dropboxusercontent.com/u/1018963/Articles/HowSpotifyBuildsProducts.pdf). Aquí se habla de formas de llevar a cabo las ideas, de promover la creación de las mismas por parte de todos los implicados en el proceso de creación y de cómo evaluar cuáles merecen la pena y cuáles no. Muy recomendable.
Gestión del tiempo
Como extra, un comentario que me acaba de hacer un compañero sobre que se le va el tiempo entre correos electrónicos, llamadas, reuniones, etc. La conversación ha derivado en lo mal que solemos gestionar el tiempo y la poca importancia que le damos a lo importante frente a lo urgente. Os dejo 2 imágenes que se explican por sí solas.
Sobre la gestión del tiempo.

Ladrones de tiempo
Sobre la prioridad de los asuntos que ocupan nuestro tiempo.

Ya lo dice Fito: «no siempre lo urgente es lo importante». Es importante mirar este cuadrante antes de planificar tareas.
En resumen, que aunque algunas de estas técnicas tienen ya su recorrido y no se pueden llamar innovadoras, la aplicación de las mismas a día de hoy, sí me parece que pueda tener más por hacer, porque veo que en muchos casos, seguimos atascados en los mismos agujeros de siempre. Espero que este repaso sirva para que muchos de vosotros os planteéis si realmente estáis gestionando bien vuestro tiempo, si enfocáis vuestro esfuerzo en lo que realmente importa, el cliente o si vendéis adecuadamente entre otras cosas.
Enviar comentario /
02 Sep 2015
por
Paco Alías
Sin categoría /
Energía, Innovación y Medio Ambiente
 La economía mundial está cada vez más interrelacionada. La protección del clima y la conservación de los recursos son también dos asuntos cada vez más internacionales y hoy en día se les concede una prioridad absoluta en muchos países. Esto hace aumentar la demanda de productos innovadores que contribuyan a proteger el medio ambiente.
La economía mundial está cada vez más interrelacionada. La protección del clima y la conservación de los recursos son también dos asuntos cada vez más internacionales y hoy en día se les concede una prioridad absoluta en muchos países. Esto hace aumentar la demanda de productos innovadores que contribuyan a proteger el medio ambiente.
En un mundo donde las necesidades energéticas son cada vez mayores, la inversión en investigación y desarrollo se ha convertido en un factor clave para dar solución a los grandes problemas a los que se enfrenta el ser humano. El medio ambiente y la ecología afloran como impulsores de la innovación y el emprendimiento.
Sin embargo, aunque parece que todo el mundo “rema hacia la misma dirección”, el equipo legislativo español parece estar pensando en otras cosas. En el presente artículo analizaremos estas cuestiones.
El caso del «impuesto» Tesla

Baterías Tesla. Fuente
Recientemente (véase noticia y noticia) salió a la luz la existencia de un borrador de Real Decreto que incluye una nueva tasa para los usuarios que se conecten a la red eléctrica nacional y tengan además sistemas privados de almacenamiento de energías renovables. Esto parece una medida disuasoria y preventiva hacia las baterías Tesla, que tanta repercusión están teniendo tanto a nivel internacional como nacional, y hacia el autoconsumo eléctrico.
La alegación del gobierno al respecto, es porque la generación distribuida de electricidad (que es como denomina el Real Decreto al autoconsumo de los usuarios) no reduce necesariamente los costes de mantenimiento de las redes de transporte y distribución, ni otros costes del sistema eléctrico que deben ser cubiertos con cargo a los ingresos del sistema, y en algunos casos podría provocar costes de inversión adicionales en las redes para adecuarlas a las necesidades de esta nueva generación.
Por esta razón, al consumidor, con independencia de la modalidad de autoconsumo (salvo en caso de instalaciones aisladas e independientes de la red eléctrica nacional), se le aplicará el término fijo del peaje de acceso por la potencia contratada y el término variable del peaje de acceso por la energía consumida.El Gobierno además recuerda que será necesario tener en cuenta los costes y cargos asociados a la provisión por servicios de respaldo que requiere el sistema para garantizar tanto el balance entre generación y demanda en el horizonte diario y en tiempo real.

Impuesto solar. Hipo Popo Pota Tamo by Ramón
Esto es cierto, la red nacional necesita tener capacidad para dar suministro siempre a todos los usuarios conectados, tengan autoconsumo o no. Pero ¿justifica esto el gravamen? Respondamos a esta pregunta analizando los datos de generación eléctrica por parte de las energías renovables (en concreto el sol) y los consumos de los hogares españoles que nos muestran en esta web.
Demanda eléctrica vs generación eléctrica. Las subastas
Una familia en España, puede intentar adaptar sus consumos eléctricos a la producción solar, mediante sistemas de encendido automático de electrodomésticos, uso de agua caliente cuando los depósitos solares están cargados,… Pero a pesar de esto, sigue habiendo momentos en que se necesita luz cuando no se produce energía. En la siguiente imagen se muestran unos datos estimados de consumo para una vivienda unifamiliar en España (área degradada en azul).

Producción solar vs demanda energética familiar. DBM Ingeniería
En esta imagen, se pueden ver los consumos medios domésticos en España repartidos a lo largo del día. Si además solapamos la curva de producción solar, se observa claramente como una gran parte de la energía producida sería desaprovechada de no existir algún sistema de almacenamiento, mientras que buena parte del día (en concreto la noche) no se podría llevar una vida normal si no es con un aporte extra (ya que no hay producción energética solar).
Propuesta regulatoria
Tal y como está planteado el Real Decreto actual o las anteriores propuestas, se está disuadiendo a cualquier posible usuario de autoconsumo o inversor de invertir en energías renovables que reduzcan su propio consumo energético, ya que los costes fijos (que son los más caros) no se verían afectados por la inversión y se mantendrían igual. También se disuade al posible inversor de auto-producir energía, debido a los recargos que conlleva. Además, el exceso de energía no se contempla el verterla en la red de Red Eléctrica Española.
Por tanto, mi propuesta es fomentar en vez de restringir, limitar o desincentivar. Pero fomentar el uso según las propias necesidades del sistema nacional, en vez del sistema propio. Y en caso de que se quiera cobrar por el mantenimiento de las redes y la disponibilidad de servicio (como está reflejado ahora en los Reales Decretos), se debería hacer sobre la energía comprada a la red, incentivando que esta sea la menor posible, y obligando a vender la energía cuando la red nacional lo necesite (por medio de acumulación en baterías por parte del usuario).
El Medio Ambiente como restrictor
Protocolo de Kioto
El Protocolo de Kioto sobre el cambio climático es un protocolo de la Convención Marco de las Naciones Unidas sobre el Cambio Climático (CMNUCC), y un acuerdo internacional que tiene por objetivo reducir las emisiones, en un porcentaje aproximado de al menos un 5 %, dentro del periodo que va de 2008 a 2012, en comparación a las emisiones a 1990, de los seis gases principales del efecto invernadero que causan el calentamiento global:

Protocolo de Kioto
- dióxido de carbono (CO2),
- gas metano (CH4) ,
- óxido nitroso (N2O),
- hidrofluorocarburos (HFC),
- perfluorocarbonos (PFC),
- hexafluoruro de azufre (SF6).

Protocolo de Kioto
En general el Protocolo de Kyoto es considerado como primer paso importante hacia un régimen verdaderamente mundial de reducción y estabilización de las emisiones de gases de efecto invernadero. Y proporciona una arquitectura para cualquier acuerdo internacional sobre el cambio climático que se firme en el futuro. El Protocolo ha movido a los gobiernos a establecer leyes y políticas para cumplir sus compromisos, a las empresas a tener en cuenta al medio ambiente a la hora de tomar decisiones sobre sus inversiones, y además ha propiciado la creación del mercado del carbono.
El protocolo de Kioto, acabó oficialmente en el año 2012, pero sigue utilizándose, y en Europa se ha heredado la estrategia 20-20-20, que básicamente pretende reducir un 20% la emisión de gases de efecto invernadero, tener un 20% de producción renovable y mejorar un 20% la eficiencia energética.
Medio Ambiente como impulsor de la innovación
Existen muchas empresas que han utilizado innovación basada en el medio ambiente. Desde la mencionada al inicio del artículo, Tesla, hasta pequeños trabajadores, autónomos y PYMES. A continuación se describen algunos ejemplos.
DBM Ingeniería

DBM Ingeniería
La crisis económica que ha sufrido el país, ha provocado también una profunda crisis en el sector de la construcción. Esto provocó que muchos profesionales de la construcción, tanto titulados como no titulados, se quedarán sin empleo. En este contexto negativo, el ingeniero industrial responsable de DBM Ingeniería, optó por reenfocar su trabajo hacia proyectos de eficiencia energética y energías renovables, sin perder la línea de trabajo principal de gestión de proyectos de instalaciones para la edificación, que en ese momento estaba parada.
DecoraLola

Caja de frutas reciclada by DecoraLola
Por otro lado, DecoraLola es una artesana de la madera, estudiante de decoración. Se dedica a la creación y restauración de muebles y elementos decorativos. Destaca como valor añadido y elemento diferenciador el empleo y uso de materiales recuperados y/o reciclados. Un ejemplo de su trabajo son sus famosas cajas de frutas reutilizadas. Las utiliza, sobretodo, como packaging, cestas de regalo y como organizadores.
Optimisee
Optimisee es una PYME de servicios y tecnologías de la información de reciente creación que se dedica a proveer al mercado de soluciones de optimización y eficiencia que consigan un significativo ahorro energético, mejorando la asignación de recursos y la capacidad del centro de datos, maximizando los beneficios empresariales haciendo uso responsable de recursos y contribuyendo al desarrollo del crecimiento económico sostenido. Para ello se ha aliado con Machine To Cloud Solutions, como empresa proveedora de Tecnología inalámbrica.

Normativa, Inversores, clientes…
Hay muchas razones por las que innovar en relación al medio ambiente. Como hemos visto, muchas veces es el entorno económico el que te incita a innovar. Otras veces, es la propia conciencia ambiental de los responsables de las empresas. Sin embargo, hay ocasiones en las que las empresas se ven forzadas a ello. Clientes, proveedores e inversores, tienen mucha fuerza a la hora de la verdad.
Financiación europea

La financiación europea, en el marco del programa Horizonte 2020 incluye el medio ambiente y las energías sostenibles en varios de sus retos sociales:
- Energía segura, limpia y eficiente,
- Acción por el clima, medio ambiente, eficiencia de los recursos y materias primas.
Todas las actividades financiadas con este programa tendrán un enfoque basado en dar respuesta a los retos que afronta la sociedad, incluyendo investigación básica o aplicada, transferencia de tecnología o innovación. Centrándose en las prioridades políticas sin predeterminar las tecnologías o soluciones que deben desarrollarse.
Enviar comentario /
19 Ago 2015
por
eestevezcontreras
Sin categoría /
El Software Libre como Motor de Innovación en IT
En Agosto de 1991, Linus Torvalds, en aquel momento un estudiante más de Ingeniería del Software de la Universidad de Helsinki, envió un correo a la lista USENET advirtiendo de sus intenciones de desarrollar un nuevo sistema operativo:
“I’m doing a (free) operating system (just a hobby, won’t be big and professional like gnu) for 386(486) AT clones.”
En poco tiempo, un grupo de entusiastas formado por estudiantes y profesionales de la programación de todas partes del mundo, se fue involucrando compartiendo ideas y código. Este grupo de desarrolladores que trabajaban de forma altruista y motivados por crear algo que muchos otros como ellos pudieran usar y mejorar, pronto se convirtió en uno de los mayores ejemplos de proyecto colaborativo en la historia reciente de la Informática. Aunque es uno de los más famosos ejemplos, está bastante lejos de ser el único, aunque todos ellos han demostrado como un grupo de usuarios y tecnólogos con perfiles e intereses completamente distintos, han sido capaces, por si mismos, de dirigir proyectos de gran complejidad técnica.
Después de casi 25 años, hoy en día, Linux está presente en casi el 54% de los dispositivos móviles, en casi el 37% de los servidores web, en el 97% de las instalaciones de super computadores y en casi el 30% de los sistemas embebidos entre otros. Ha permitido además el desarrollo de multitud de empresas que directamente han utilizado Linux como la base de su negocio, tales como Red Hat y Ubuntu, poniendo de manifiesto un aspecto esencial: el software libre se puede monetizar.
En la actualidad, el Software Libre ha pasado de ser una actividad impulsada únicamente por una comunidad de hackers y activistas a convertirse en un modelo de distribución establecido globalmente que ha cambiado por completo la industria.
El papel del Software Libre en la Industria
La adopción global del Open Source como cultura y como modelo de negocio en la Industria del Software, ha tenido un papel determinante y catalizador en su desarrollo. Hoy en día, cuesta pensar en algún campo dentro del mundo de la computación en el que el Software Libre no tenga un papel relevante: cloud computing, Saas, bases de datos de nueva generación, dispositivos móviles y un largo etcétera. A la expansión del Software Libre han contribuido todos los agentes de la industria, desde Universidades y Centros Tecnológicos hasta empresas de todo tipo y tamaño, incluyendo también las grandes compañías de Internet como Google, Facebook, Twitter. En el contexto actual, por tanto, dónde la apuesta por el Software Libre se ha consolidado y dónde los viejos prejuicios de la comparación con el Software propietario se han vencido, cabe preguntarse cuáles han sido los factores que han llevado a la situación actual.
Industrialización del Software
Indudablemente, el Software Libre ha propiciado el cambio en el sector que ha permitido pasar de una actividad casi artesanal a una verdadera industria. Si nos paramos a pensar por un momento en los procesos productivos de cualquier otro tipo de industria, veremos que la mayoría de ellas se basan en el ensamblaje de pequeñas piezas que se van uniendo para construir sistemas más complejos. En los inicios de la industria del software, este concepto de ensamblado no existía, por lo que cada desarrollo se hacía desde el principio hasta el final de manera distinta, con costes elevados y sin posibilidad de producir en masa.
Aunque aún estamos muy lejos de ser una industria dónde la producción pueda asemejarse a una línea de ensamblado, si es cierto que en la actualidad cualquier desarrollo Software se realiza en base a componentes, herramientas, librerías y Frameworks ya existentes y disponibles de forma abierta. Una de las señales claras de que este hecho se ha producido es que en el desarrollo de software cada vez se habla más de Integración que de Implementación.
Adopción del Software Libre Vs Software Propietario

La adopción generalizada del Software Libre por parte de las empresas actuales de IT radican en cuatro aspectos clave: costes, libertad de elección, seguridad (calidad) y facilidad de uso. El coste, aunque pudiera parecer el más determinante de todos ellos y a diferencia de lo que mucha gente piensa, no es el aspecto más importante. Dejando a un lado el debate de las distintas licencias que existen y que toda empresa debería conocer antes de incorporar cualquier herramienta abierta, en la última encuesta sobre el Futuro del Software Libre realizada cada año por la consultora Black Duck en la que se pregunta a más de 800 empresas, tanto proveedoras como consumidoras de Software, sobre distintas cuestiones relacionadas con el Software Libre, revelaba que el primer motivo para adoptarlo por delante de soluciones propietarias era poder protegerse contra el «lock-in» de los proveedores. Al disponer del código fuente, las empresas puedan adaptar las herramientas a sus necesidades y no necesitan estar atadas a las decisiones de los proveedores.
El segundo motivo más repetido fue el de poder disponer de Software de calidad. Efectivamente, las herramientas de Software Libre más extendidas han sido probadas y usadas por una cantidad de desarrolladores de la que ninguna empresa del mundo puede disponer. Existe también transparencia en cuento al estado de los proyectos, listas de correo de soporte, bug trackers, documentación actualizada, etcétera. Si unimos esto a que el desarrollo de los proyectos suele estar guiado por las necesidades de la comunidad y de los usuarios, las empresas pueden tener una seguridad alta en la adopción de nueva tecnología con un nivel bajo de riesgo.
El concepto de Comunidad. Innovación abierta
Tradicionalmente, las innovaciones estratégicas han sido consideradas como uno de los activos competitivos más valiosos para las empresas y como una fuente de ventajas competitivas frente a la competencia que debe protegerse internamente. Este tipo de desarrollo propietario y de estrategia competitiva es característica de la innovación cerrada, dónde el progreso tecnológico se mantiene secreto o se protege intelectualmente esperando un retorno de la inversión.
En contrapunto, colaborar y compartir han sido siempre los principios claves dentro del mundo del Software Libre. Los beneficios de los principios de la innovación abierta (incorporar tecnologías innovadoras desde fuera de la organización, contribuir las invenciones desarrolladas internamente y hacerlas llegar al máximo número de personas posibles, trabajar colaborativamente con agentes externos a la organización, etcétera) han sido ampliamente aceptados desde sus inicios en las comunidades de Software Libre. Además, estas comunidades, son ejemplos perfectos de equipos de trabajo con una cultura que favorece la innovación: multidisciplinares, open-minded, horizontales, basados en meritocracia, etcétera.
En un entorno abierto, la estrategia de una compañía para permanecer competitiva pasa por intentar utilizar todos los recursos disponibles para el desarrollo continuo de nuevos productos y servicios. En los últimos años en la industria del Software, se está imponiendo la innovación abierta como estrategia para que comunidades de usuarios (agentes externos) permitan mejorar los desarrollos internos de una empresa.

A finales de 2014, Facebook contaba con 107 proyectos open-source en su cuenta de Github. Recientemente, el responsable de Software Libre de Facebook, James Pearce, daba tres razones principales por las que Facebook abría todos sus proyectos:
- Ideología: desde sus inicios, Facebook se construyó usando herramientas de Software Libre como Linux, Apache, MySQL, PHP, etcétera, por lo que sentían la obligación moral e ideológica de contribuir tecnología de vuelta.
- Innovación: quizás la principal razón por la que cualquier compañía o desarrollador Freelance contribuye su trabajo es por que puede escalar y mejorar más rápidamente cuando muchas mentes distintas trabajan en los mismos problemas. Según James, en Facebook «creemos que podemos ser más competitivos si la industria en conjunto es más competitiva y es capaz de innovar en el mismo tipo de problemas a los que nos enfrentamos día a día», es decir, lo que es bueno para la industria, es bueno para Facebook. Igualmente, cuando un desarrollador sabe que su código puede ser usado e inspeccionado por cualquier persona en todo el mundo, se esfuerza mucho más en hacerlo correctamente. En la actualidad, Facebook cuenta con más de 1.000 contribuciones externas a sus proyectos que suponen un porcentaje elevado del código con respecto a las contribuciones internas, resultando un claro caso de éxito en la innovación abierta.
- Beneficios para el negocio: la cultura Open Source que mantienen les permite atraer talento con mucha facilidad, mejorar su tecnología y ser un referente en muchos ámbitos tecnológicos dentro del Software.
Aunque hablamos de una de las grandes empresas tecnológicas de este siglo, como veremos a continuación, estas razones son extrapolables en gran medida a empresas de Software de cualquier tamaño.
Software Libre como Estrategia
Estratégicamente, Facebook no tiene ningún problema para liberar la mayoría de sus desarrollos tecnológicos principalmente por que el core de su negocio no se basa en ellos. Facebook no es una empresa de tecnología al fin y al cabo, es una empresa de contenidos. La tecnología es un medio para soportar su estrategia de negocio y su visión con respecto al Software Libre es la de liberar sus desarrollos para mejorarlos y hacerlos sostenibles. Evidentemente, esta estrategia no es válida para todas las empresas de la industria.
Desde sus inicios, han surgido distintas formas de monetizar el Software Libre. El pionero en este aspecto fue Red Hat, quien decidió por primera vez ofrecer de forma totalmente gratuita todos sus productos y cobrar por mantenimiento, soporte y servicios profesionales. MySQL optó por un sistema dual de licencias, ofreciendo su base de datos con licencias Open Source no comerciales y licencias comerciales. Las licencias no comerciales, impedían a otras empresas realizar desarrollos sobre MySQL sin distribuirlos con la misma licencia, mientras que la licencia comercial lo permitía a cambio de una cuantía económica. Otras empresas como Alfresco ofrecen dos versiones distintas de sus productos, una versión Open Source con menos funcionalidades y sin soporte y otra versión Enterprise licenciada que incluye soporte y otros beneficios. Esta estrategia es muy útil para que las posibles clientes puedan tener una idea inicial del producto.
En los últimos años, han surgido nuevas estrategias alrededor de los proyectos de Software Libre. Una de ellas es la de desarrollar versiones Enterprises, en la nube o nuevos productos encima de los proyectos que faciliten su uso a las empresas y reduzcan la complejidad de adopción. Podemos citar ejemplos famosos como Cloudera, principal compañía detrás de Hadoop o LucidWorks, detrás de Apache Solr. Estas empresas han conseguido que los consumidores de estas tecnologías hayan asociado el nombre de los proyectos o herramientas al nombre de la empresa. Muchas compañías no pueden contar con expertos en estas tecnologías o incluso contando con ellos, es muy probable que acaben comprando sus productos al reducir los costes de integración, mantenimiento y soporte.
Estrategia en las PYMES
En mi opinión, cualquier empresa de IT de cualquier tamaño debería contar con una estrategia de Software Libre adaptada a sus peculiaridades. La pregunta que surgirá en todas las ocasiones será: ¿qué podemos y qué no podemos abrir?. Aunque la respuesta puede tener muchos matices, está claro que siempre deberemos proteger aquellos desarrollos que directamente soporten nuestro modelo de negocio, nuestra diferenciación o valor añadido con respecto a la competencia. No tendría sentido liberar aquel código que permitiera a la competencia ofrecer los mismos servicios.
En general, a modo de conclusión, dependiendo de la actividad de la empresa, la estrategia de Software Libre a implantar podría seguir alguno de los siguientes supuestos:
- Liberar side-projects: en ocasiones las empresas realizan proyectos paralelos para cubrir alguna necesidad interna concreta o bien alguna funcionalidad exigida en un proyecto de cliente (por ejemplo, un plugin de alguna herramienta ampliamente usada en el mercado). Liberar estos proyectos y permitir que otros puedan usarlo y mejorarlo contribuye, por un lado, a mejorar la reputación de la empresa en cuento a su experiencia en una tecnología concreta y por otro a ir forjando una comunidad de colaboradores externos a la organización. Una empresa que demuestra públicamente que puede desarrollar código de calidad en una tecnología concreta tiene más posibilidades de encontrar clientes que aquellas que guardan sus desarrollos específicos en un cajón. Por ejemplo, en Athento, hemos liberado varios plugins del Gestor Documental Open Source Nuxeo, esperando, por un lado esperando un retorno tanto de la comunidad como de nuestros clientes y usuarios y demostrando nuestra experiencia con esta herramienta por otro.
- Liberar partes del producto: al igual que en el caso de Facebook, cualquier empresa que desarrolle productos Software, puede optar por liberar partes de sus desarrollos dentro de una estrategia de innovación abierta con el objetivo de mejorarlas. Habrá que seleccionar cuidadosamente que componentes queremos liberar. Por un lado deben ser importantes dentro de la estrategia tecnológica de la empresa y por otro no poner en peligro nuestra ventaja competitiva.
- Formar parte de la comunidad: si una empresa tiene amplia experiencia en el uso e integración de alguna herramienta de Software Libre, debe, por un lado, contribuir de vuelta las personalizaciones del proyecto realizadas y, por otro, intentar posicionar a sus desarrolladores como colaboradores oficiales o «committers» de los proyectos. Involucrarse activamente en la comunidad es una forma de obtener más experiencia en la herramienta y de que posibles clientes puedan relacionar a nuestra empresa con ella.
4 comentarios /
20 Jul 2015
por
rharo
Sin categoría /
Algunas experiencias sobre las gestión de proyectos
En esta nueva entrada de mi Blog, me gustaría hablar de la gestión de proyectos y dar mi punto de vista desde la experiencia que tengo de esta maravillosa, apasionante y “tranquila” profesión. Llevo 7 años dedicándome a la gestión de proyectos: 6 años en un centro de investigación y un año en un centro tecnológico. Bien, mi opinión es que no tiene nada que ver, me explico, en un año he pasado de solicitar y escribir proyectos de investigación médica básica centrados en Salud y en Ciencia Excelente a escribir proyectos más relacionados con mercado y planes de negocio… Por mi formación en Farmacia, no me ha resultado sencillo cambiar de registro y de “TRL” tan fácilmente, pero teniendo en cuenta una frase muy importante que aprendimos en el máster, la formación es imprescindible a la hora de escribir un buen proyecto europeo. Es imposible hacer un buen plan de negocios, vender una idea feliz que se convierta en un producto que vaya a salir a mercado sino sabes por dónde empezar. Por resumir, yo diría que existen una serie de puntos mágicos que se deben cumplir y seguir para hacer una buena gestión:
- Aparte de conocer bien cuál es el panorama en la CE, también es conveniente buscar convocatorias de fundaciones privadas (en EEUU son muy filantrópicos), que es cierto, que no aportan tanta financiación, pero son menos competitivas. El hecho de conocer las distintas convocatorias, no es sencillo, y exige una búsqueda continuada y precisa. Es necesario tenerlas localizadas con tiempo suficiente para poder prepararlas bien.
- “Empollarse” la convocatoria, ¿qué tipo de proyectos financian?¿podría estar mi idea financiada por esta convocatoria? ¿qué partidas financian( personal, equipos…)? No merece la pena perder el tiempo en escribir una propuesta que sabes que no va a ser financiada porque el “scope” de la convocatoria no se adapta a tu idea de proyecto.
- Tener los recursos necesarios para escribir una propuesta competitiva, personal formado y cualificado, sino contestamos claramente y de forma concisa a lo que piden en cada punto de la propuesta…estamos perdidos. Hay que tener en cuenta que los evaluadores la mayoría de las veces no son expertos en cada uno de las propuestas que tienen que evaluar y tienen vida laboral y supongo que vida personal también (aunque a veces lo dudo) aparte de evaluar propuestas. Así que por favor, es mejor darles el trabajo hecho, no poner parrafadas, usar gráficos , tablas…para que si por desgracia la tuya es la décima propuesta que se leen después de un largo día de trabajo con sus hijos gritando por la casa, que les sea sencillo leerla y entenderla bien, ganaremos puntos!
- Poder llevar a cabo la ejecución del proyecto…que luego vienen los sustos! No pidamos proyectos que no vamos a poder llevar a cabo por falta de personal, equipamiento, u otros recursos…nadie lo diría, pero muchas veces es complicado justificar el proyecto sino se ha planificado bien desde el primer momento y la Comisión Europea no es tonta…se enteran de todo.
- Al hilo de lo anterior, gestionar el proyecto de una manera eficiente y tener todas las actividades y su coste bien controladas, si existe algún cambio en la ejecución del proyecto (que siempre existen) es necesario solucionarlo cuanto antes y/o comentárselo al Project Officer del proyecto (son personas y lo entienden), es importante no dejar que la bola se haga cada vez más grande, ya que luego es muy difícil de solucionar y justificar. Los Planes de contingencia son esenciales.
- Las auditorías de gastos son como las “meigas, que haberlas hailas”, no crees en ellas, no las ves, pero el día que llega la carta de la CE con los proyectos que te van a auditar empiezas a temblar, desde la notificación de la carta tienes un mes para preparar toda la documentación que te piden… entonces, tomas aire y te tranquilizas, porque tienes todo bien guardado , incluso los proyectos terminados hace 5 años que pueden auditarte también, los timesheets firmados y sellados, los informes realizados , las facturas con importes más elevados controladas y tres ofertas de cada subcontratación, así como resguardos de los viajes y tickets…entre otras cosas. El susto de esta forma, no es para tanto, así que te sientas a descansar esperando a que venga el o la susodicha de la CE para enseñarle y explicarle todo lo que te pida durante su esperada visita de 3 días.. y encima luego tienes que invitarles a comer! ¿y dónde imputas luego ese gasto?
Bueno, seguro que se me olvidan mil consejos y comentarios más que podría escribir, pero aunque parezca complicado y aburrido, lo cierto es que me encanta mi trabajo ( y eso que caí aquí por casualidad) porque cada día es diferente y supone nuevos retos que afrontar y que la mente nunca pare quieta, eso sí, los días anteriores al deadline no se los deseo a nadie 🙂 . La innovación y el sentido común deben ser parte de nuestra vida, sino nunca podremos seguir avanzando.

8 comentarios /
10 Dic 2016
por
Ana
Sin categoría /
¿POR QUÉ LE ESTARÉ PEGANDO YO A ESTE MONO?
Hace algún tiempo un amigo me contaba la siguiente historia que os voy a contar. Lo cierto es que aunque el experimento fue hecho con chimpancés, podemos ver enormes similitudes con lo que a todos nos pasa diariamente. Y es que no siempre sabemos el motivo por el cual hacemos algo, simplemente lo hacemos sin cuestionarnos porqué lo hacernos así. Esta es la historia (experimento):
Un día, un grupo de científicos introdujo a cinco chimpancés en una habitación donde había un manojo de plántanos colgado del techo. La única manera de llegar a ellos era mediante una escalera debidamente situada bajo el manojo. El experimento se diseñó de tal forma que cuando uno de los monos subía a la escalera para alcanzar los plántanos, automáticamente el resto de los monos era bañado con agua muy muy fría.
Los monos se dieron cuenta muy pronto de lo que pasaba y aprendieron rápido a ponerle solución. Así que, para cuando el tercer mono intentó subir por la escalera, los otros simplemente le dieron una paliza antes de que pudiera alcanzar los plántanos y evitar así el castigo del agua. Pasado un rato, ninguno se dejaba llevar por la tentación de subir a coger plátanos, so pena de recibir el correspondiente correctivo.
Poco después, los científicos sustituyeron uno de los monos por otro nuevo que, obviamente, no sabía nada del agua. Este al percatarse del manojo de plátanos, raudo se dispuso a intentar cogerlos. Pero antes de que este fuese capaz de acercase a la escalera, el resto de monos ya le había impuesto el debido castigo. Poco a poco, los científicos fueron cambiando a todos los monos hasta que no quedó ninguno de los que originariamente había recibido el baño de agua fría. Sin embargo, los nuevos monos seguían sin atreverse a subir por la escalera y pegaban a todo aquel que se acercaba a ella, a pesar de que ninguno de los cinco monos que ahora había en la habitación había recibido baño alguno.

En la vida en general y en las empresas en particular sucede lo mismo. Constantemente hacemos las cosas de manera similar a como las hacen los demás, por el simple hecho de que asumimos que si el resto lo hace, esa debe ser la forma de hacerlo. Esto abarca cualquiera de las actividades que realizamos, desde el marketing hasta el desarrollo de nuevos productos. De igual manera, cuando las empresas salen a comercializar sus nuevos desarrollos, se encuentran con las reticencias al cambio y la existencia de inercias que en ocasiones son muy difíciles de vencer. Tanto que a veces es mejor ser creativos para sortear dichas inercias que intentar enfrentarse a ellas o cambiarlas. Esto es, adaptarse al medio en lugar de intentar que el medio se adapte a ti.
Recientemente, llegó a mis oídos una idea de estas que deja muy claro lo que estoy comentado. Tesla Bikes es una empresa holandesa que comercializa bicicletas eléctricas, que incorporan gran cantidad de componentes electrónicos. Un producto altamente sofisticado, caro y delicado, sobre todo si se compara con una bicicleta al uso. Pues bien, tenían el enorme problema de que las bicicletas resultan continuamente dañadas durante el transporte. Además, ninguna de las soluciones aportadas conseguía solventar el problema de manera definitiva y sólo encarecía la logística del producto.
Es aquí donde se les ocurre una idea brillante. Deciden imprimir en la caja, en lugar de una bicicleta, la imagen de una pantalla de televisión con una bicicleta dentro. Esto, de algún modo, consiguió que mejorase el trato que los transportistas destinaban a sus paquetes, reduciendo los daños ocasionados durante el transporte en un 70-80%.

Lo que la empresa hizo fue adaptarse al medio, consiguiendo obtener para sus productos el trato que los trasportistas ya daban a los televisores, sin intentar producir cambio alguno en ellos. Esto es un claro ejemplo de cómo adaptarse al medio y “pensar fuera de la caja” (“think out of the box”); para lo cual es necesario que siempre nos preguntemos: ¿POR QUÉ LE ESTARÉ PEGANDO YO A ESTE MONO?
Enviar comentario /
28 Nov 2016
por
esuarezmartin
Sin categoría /
Se busca innovacion en la Apicultura
Decía Einstein que sin las abejas la vida en la tierra no duraría mas de cuatro años, o bien fue una frase atribuida a este último por apicultores franceses en huelga. Sea verdad o no, lo cierto es que la importancia de las abejas para la naturaleza es innegable a través de varios aspectos de la naturaleza
La actividad de la apicultura lleva produciéndose milenios, si bien el aprovechamiento de la miel es de suponer que se realiza desde el principio de los tiempos. No es objeto de esta entrada hacer un repaso en la historia de la apicultura hasta nuestros días, pero cabe destacar que los mayores avances en la apicultura se realizaron (como en muchas otras formas de explotación industrial) al final del siglo XIX y principios del XX.

Venían dadas estas mejoras por agricultores que se dispusieron a la experimentación basada en la experiencia propia durante años de pequeñas modificaciones sin base científica o académica.
Ahora en pleno siglo XXI la apicultura se enfrenta a unos retos de gran envergadura. El principal producto, la miel, no ha cambiado su composición en millones de años, la creciente mortalidad de las colmenas sin causas aparentes, el aumento de enfermedades y depredadores, el uso de químicos sintéticos en la agricultura, el abandono del mundo rural y una demanda de producto creciente son los aspectos a tener en cuenta para introducir la innovación en esta actividad.
En mi opinión, las innovaciones realizadas en las últimas décadas se han basado en perfeccionar o adaptar técnicas a zonas concretas, mejorar herramientas, o hacer el trabajo de apicultor lo más rápido y llevadero posible. Pero no se ha alcanzado ninguna innovación disruptiva, nada que haya marcado un antes y un después, ningún cambio que marque la diferencia.
Los materiales y las formas con los que se hacen las colmenas, los trajes de apicultor, y la gran mayoría de los procesos son los mismos que en el siglo pasado.
Por qué innovar?
- Población decreciente y mortalidad de los enjambres. Por varios factores
- Varroa y otras enfermedades (varroosis, virosis o nosemosis). Es un parásito habitual en las abejas pero en la últimas décadas su número ha aumentado tanto y no se ha encontrado un tratamiento efectivo, se ha convertido en el enemigo número 1 del apicultor y por supuesto de las abejas.
- Agroquímicos y pesticidas en la agricultura. Abejas y plantas conviven en un mismo habitat. El abuso en los pesticidas incide en la mortalidad y bajo rendimiento de las abejas que entran en contacto con estos productos de origen humano.
- Avispa asiatica (Vespa velutina). En el territorio español, la introducción de esta especie que actúa como depredador de las abejas supone ya un problema de primer nivel en el norte de la península.
- Otros factores menos cuantificables como el cambio climático, la contaminación, la pérdida y fragmentación de hábitats; y el mal uso de algunas técnicas en la apicultura serían causas directas en la desaparición de las abejas a nivel global.
- Demanda creciente de miel y productos derivados (polen, propóleos, cera etc). En el mercado europeo ya es mayor la demanda que la oferta. Eso ha supuesto la entrada de miel procedente de China y otros países sin controles. Existe también un debate sobre la calidad y adulteración de la miel debido a que la demanda ha aumentado los precios.
- Factor de desarrollo rural y generador de empleo. La apicultura ha demostrado que puede transformarse en una herramienta idónea para el desarrollo territorial, fundamentalmente en la agricultura familiar y sobre la base de modelos asociativos. El sector apícola se encuentra conformado casi exclusivamente por pequeños apicultores.
Dónde innovar?
- Tratamientos para las enfermedades comunes de las abejas. Las principales empresas químicas a nivel mundial ofrecen productos para estos tratamientos. Aun sin ser totalmente efectivos, se encuentran con escasa «competencia» en tratamientos caseros o ecológicos.
- Desarrollo del enjambre en la colmena. Los modelos de colmena actuales (para explotación) son basados en diseños del siglo XIX. La búsqueda de enjambres de mayor tamaño (mayor producción) o mas resistentes a depredadores y enfermedades serían objeto de mejora.
- Mecánica agrícola. La adopción de las nuevas tecnologías en este entorno aún tiene margen para conseguir cambios en un entorno donde no se suelen hacer grandes inversiones.
Quién innova?
Son difíciles de encontrar aportaciones públicas en investigación e innovación. El carácter propio de la actividad llevada a cabo principalmente por empresas pequeñas hace difícil la agrupación del sector en torno a un Centro Tecnológico, salvo excepciones a nivel autonómico.
Una búsqueda rápida a videos sobre innovación en apicultura nos dará la imagen de la falta de estudios e investigación en este campo
https://www.youtube.com/results?search_query=innovacion+apicultura
Un ejemplo de innovación con tecnología financiada por la Unión Europea
Enviar comentario /
28 Nov 2016
por
neftaligonzalez
Sin categoría /
Redes Inteligentes Electricas
Las Smart Grids (redes inteligentes de Energía) suponen una revolución sin precedentes en el mundo de la generación, transporte y distribución de energía a través de redes eléctricas.
La UE ha establecido una Directiva Europea 2009/72/EC en la que recomienda a sus países miembros que en 2020 más del 80 % de los contadores y redes eléctricas sean inteligentes.
En el caso puntual de España, este hito debe cumplirse para el año 2018, y de momento las empresas están centradas en este hito de cambio de contadores y no en la explotación de datos que estos generan. Pero este no es el caso solo de España, si revisamos diferentes estudios en el mundo nos encontramos con diversidad de situaciones que nos hacen pensar que las redes inteligentes aun esta por eclosionar y no se aprovechan al máximo.
Las empresas eléctricas poseen una extensa red que está llena de energía pero que a su vez poseen sorprendentemente pocos datos sobre esta energía.
Las empresas eléctricas no pueden analizar o detallar muy profundamente las miles de subestaciones, centros de transformación y demás elementos que conforman su red eléctrica, a pesar de que ya existen gran diversidad de equipos y tecnología que lo permiten.
Algunas empresas todavía se enteran de un corte de electricidad en el vecindario, no porque aparezca en alguno de sus sofisticados equipos de monitoreo, sino porque los clientes los llaman por teléfono y se quejan de que la electricidad está fuera de servicio.
Las empresas eléctricas obtendrán una gran cantidad de información en tiempo real de hogares, negocios, fabricas, plantas de energía y de su propia infraestructura de generación, transmisión y distribución de energía.
Uno de los grandes desafíos que enfrentan las empresas eléctricas y proveedores de tecnología esta asociado a la escasez de información en tiempo real y como gestionar y darles utilidad a grandes volúmenes de datos.

Una vez que las empresas eléctricas y los consumidores dispongan de información más detallada sobre el uso de la energía y demanda para él se puede manejar más eficientemente.
Por ejemplo, los consumidores podrían ser guiados para trasladar sus consumos en las horas punta y con ello poder reducir la necesidad de uso de medios de generación menos eficientes y más contaminantes de aquellas centrales eléctricas que no usen energías renovables.
Este es un ejemplo sencillo de como se podrían beneficiar ambas partes (empresa y cliente) y a su vez mejorar el medio ambiente.
Pero antes de que esto pueda ocurrir de forma general, las empresas electricas deben prepararse para una avalancha de datos, como lo han hecho otras industrias. El reto de actualizar los sistemas de TI en consecuencia es una de las razones por las que las redes inteligentes están aun en fase de desarrollo. Jeff Tatt (Cisco) experto en este tema comenta: «Lo que las empresas de energía están a punto de experimentar no es simplemente duplicar o triplicar la cantidad de datos que van a obtener», este cambio, va a ser un aumento de varias órdenes de magnitud. La industria lo sabe y lentamente está haciendo la transición. Pero la energía es una de esas áreas en las que no se puede simplemente arrancar todo y empezar de nuevo «. Un desafío adicional para las empresas eléctricas es que ejecutan sus operaciones de control central en una mezcla de sistemas informáticos heredados, la mayoría de los cuales no pueden comunicarse entre sí.
«He estado en salas de control donde los operadores necesitan sentarse en sillas y girar entre seis monitores diferentes para mantener todo funcionando», dice Glenn Booth, jefe de marketing de Green Energy, que proporciona el software de gestión de red de próxima generación. «Estamos hablando de nuestra red eléctrica nacional aquí, y esa no es la forma en que deberíamos estar manejando las cosas». Es relativamente simple equipar una casa con un «contador inteligente» que puede generar datos con mucha frecuencia de información sobre el uso de energía en la casa. Pero debido a que la mayoría de las empresas de servicios públicos simplemente no tienen los sistemas informáticos para transmitir o almacenar estos datos, los que ya han instalado contadores inteligentes generalmente usan muy pocos datos o simplemente reducen la cantidad de información a extraer de los contadores, esto con la finalidad de no verse abrumados con datos que no pueden manejar. Las empresas eléctricas que hallan desplegado contadores inteligentes o modernizado su infraestructura eléctrica necesitarán «complejos motores de procesamiento de eventos» que todavía están en proceso de desarrollo.
En el caso particular de España el despliegue masivo de los contadores inteligentes deberá estar terminado para el 2018.
De momento las empresas eléctricas están aunando esfuerzos para poder cumplir con los hitos de instalación de contadores, de momento sin sacarle el máximo provecho a toda la información generada por los contadores inteligentes.
A mi juicio personal, el caso de España creo que pillo un poco desprevenidos a las empresas eléctricas, ya que se trabajó mucho en adoptar normas y estándares para los contadores tanto a nivel metrológico, como a nivel de comunicaciones, pero no se trabajó en la nueva gestión de la información que viene de los contadores inteligentes.
Os pongo un ejemplo de volúmenes de datos que se pueden obtener de un contador inteligente versus un contador mecánico de tecnología antigua.
| Contador Inteligente | Nro de Lecturas | Magnitudes de Energía | Total | |
| Lecturas Diarias | 365 | 6 | 2190 | |
| Lecturas Mensuales | 12 | 6 | 72 | |
| Lecturas Horarias | 8760 | 6 | 52560 | |
| Eventos | 300 | 1 | 300 | |
| 55122 | ||||
| Contador Mecánico | ||||
| Lecturas Diarias | 0 | 1 | 0 | |
| Lecturas Mensuales | 12 | 1 | 12 | |
| Lecturas Horarias | 0 | 1 | 0 | |
| Eventos | 0 | 1 | 0 |
En esta tabla se puede apreciar que en un año el volumen de datos, de un contador inteligente a un contador tradicional tiene un incremento de volumen de información del 4593,5 %, ahora multipliquen esta cifra para millones de contadores y os daréis cuenta de la magnitud de datos de las que os estoy hablando.
Los grandes retos de modernización para las empresas eléctricas de su infraestructura no solo comienzan con la modernización e instalación de contadores, sensores a través de las redes eléctricas, el reto real es poder sacarle provecho útil a esta información y para ello necesitan manejar grandes cantidades de datos, por lo que se requerirá de una infraestructura adecuada.
Bien, espero que este pequeño articulo haya servido para poder ilustrar de manera real la situación de las redes eléctricas inteligentes y mi visión sobre ellas.
Saludos
Enviar comentario /
28 Nov 2016
por
moutumuro
Sin categoría /
Brisa, La bicicleta terapéutica del futuro en nuestras manos
En la encuesta Nacional de Salud 2011-2012 se apuntó en el caso de la obesidad, que ha pasado de afectar al 7,4% de la población en 1987 al 17% en esa edición. En cuanto al sobrepeso, afectaba ya al 37% de la población mayor de 18 años.
El ejercicio, como método terapéutico es reconocido por la comunidad medico sanitaria como el principal factor de atenuación de las patologías mencionadas, especialmente si se trata de ejercicio dirigido por profesionales clínicos. Sin embargo, el rechazo al mismo y la falta de adhesión al tratamiento (continuación en el tiempo), especialmente debido a la falta de motivación, es el factor más destacado, especialmente si este se realiza en centros cerrados. La monitorización del paciente durante las sesiones de ejercicio, de forma intrusiva e incómoda, es otro agravante del abandono y la discontinuidad. Sin embargo, la falta de monitorización y/o una monitorización insuficiente, impide un correcto seguimiento del progreso de recuperación o mantenimiento, dificultando el estudio científico de resultados y la adaptación del tratamiento al paciente.
Debido a estos factores, se plantea la necesidad de crear una una «innovadora» bicicleta dotada con la última tecnología y que servirá como terapia y mejora de la calidad de vida de personas con problemas cardíacos y de obesidad provocados por la falta de ejercicio. En concreto, estas personas serán monitorizadas mediante sensores cuando realizan la actividad física con la bicicleta y recibirán asesoramiento clínico experto para mejorar su salud, su estado físico y su calidad de vida.
La idea es construir desde cero un elemento cotidiano, como es una bicicleta, dotándola de la última tecnología en monitorización, asistencia e inteligencia proactiva. La bicicleta cuenta, entre otros, con sensorización avanzada en tiempo real de parámetros vitales; medición de las emociones como complemento de sensorización; estabilidad y usabilidad optimizada; asistencia proactiva y reactiva; sistema de control y recomendación; complementos de ejercitación; modalidad ‘outdoor’ o ‘indoor’; asistente del tratamiento y entrenador personal; sistema global de control y el historial del usuario completo.
También, a través de la medición de determinados parámetros del paciente, la bicicleta detecta como se siente la persona lo que provocará subir o bajar la potencia, entre otros. Además, todo es online y el médico está conectado a la bicicleta, por lo que sabrá qué está pasando y puede cambiar los parámetros en tiempo real. Si una persona va haciendo su ejercicio como debe la bicicleta continuará igual, pero si detecta que hay cosas que no van bien, reacciona para ajustarse al momento y la persona. Así, por un lado se parametriza, entre otras variables, lo que la persona siente, medido a través de sensores y también se maneja la parte ambiental, ya que, el sistema, entre otras funciones, controla la calidad de área exterior.
No obstante, a diferencia de otras minusvalías que sí disponen de productos específicos, como, por ejemplo, sillas de ruedas o prótesis, estos no los tienen.
Cuando una persona obesa comienza a hacer ejercicio en muchas ocasiones no son capaces de mantener la rutina, hay falta de motivación y tampoco ayuda que no cuenten con el instrumento adecuado y adaptado a sus necesidades.
El proyecto ha sido subvencionado por el Centro para el Desarrollo Tecnológico Industrial (CDTI), apoyado por el Ministerio de Economía y Competitividad y cofinanciado por el Fondo Europeo de Desarrollo Regional de la Unión Europea (Feder).
El objetivo es que, tras la fase de desarrollo, el producto sea comercializado e introducción en el mercado tanto en hospitales, clínicas, centros de rehabilitación especializados, incluso para el usuario final.
Enviar comentario /
28 Nov 2016
por
jcobo
Sin categoría /
¿Un sistema educativo para el futuro o para el pasado?
Si entramos hoy en día en una clase de cualquier colegio, instituto o universidad; con mucha probabilidad sintamos viajar en el tiempo y estar en un aula de hace 50 años. Ni la forma, ni el contenido han cambiado mucho. La organización de la mesas de la clase es igual que entonces, el profesor sigue estando en el mismo sitio que antaño, realizando su clase magistral ante alumnos que no cuestionan la información y los conocimientos que reciben de él, como si de una verdad absoluta e incuestionable se tratase. Siguen dando las mismas asignaturas y temarios pero con distintos nombres que hace media década. La forma de evaluar los conocimientos adquiridos tampoco han cambiado mucho, sigue basándose en la memorización de conocimientos y recitar el papel, cual papagayo, todo lo memorizado. Además de todo ello, las asignaturas estrellas siguen siendo las matemáticas, la lengua y las ciencias, pasando a un segundo o tercer plano la plástica o la música. Parece ser que el sistema educativo y la forma de entenderlo, se ha quedado paralizada en el tiempo. Por este no han pasado los años, pero si muchos alumnos cuya realidad social y laboral presente y futura si ha ido cambiando.
El sistema educativo fue creado en plena era del desarrollo industrial. Buscaba crear trabajadores para cubrir la incipiente oferta laboral desarrollada en todas esas fábricas y creo el sistema educativo en base a ellas. Valoran la calidad del alumno como si de un producto se tratase, disponen la clase lineal y ordenada como la distribución de una fábrica. Incluso traducen los descansos de los trabajadores de las fábricas en la escuela, estableciendo en estos también un descanso, el cual recibirá el nombre de recreo.


Observemos, teniendo en cuenta lo anterior, la evolución del automóvil, la medicina o las tecnologías de la información y la comunicación tanto en nuestro país como en el resto del mundo. En todas ellas, queda latente el gran cambio que éstas han sufrido en los últimos 50 años. Hemos evolucionado desde el mecanismo de los primeros coches hasta el coche eléctrico, curamos enfermedades que antes suponían una muerte irremediable, y en segundos somos capaces de comunicarnos con una persona que está en el otro extremo del mundo, algo en lo que antes necesitábamos meses. Toda esta evolución se basa en la necesidad de adaptarse a un mundo dinámico que desarrolla exponencialmente sus necesidades económicas, personales o comunicativas y las cambio de una manera vertiginosa. Parece lógico que si nuestros deseos y necesidades para vivir cambian con el tiempo, también lo hagan los instrumentos mediante los cuales conseguimos satisfacerlos. De esa forma conseguir adaptarse al mundo y a la realidad que nos rodea y que nos caracteriza nuestro en cada momento.




Pero ¿Por qué encontramos tantas diferencias entre la evolución que presenta el sistema educativo y el de un coche en los últimos años? ¿Las necesidades y deseos de los alumnos no han cambiado?, ¿no es importante que la base principal del desarrollo futuro de cualquier sociedad se actualice ante los cambios del mundo?, ¿estamos preparando a las personas del futuro para el futuro, o para el pasado?
Ante todo lo descrito y reflexionando sobre las preguntas anteriores, queda latente la necesidad de actualizar nuestro sistema educativo, creado para una sociedad que hoy por hoy ya no existe. Es urgente implantar innovaciones que salven al sistema educativo y los que forman parte de él, los alumnos, el futuro.
Son muchas las vertientes sobre las que se ha de trabajar para conseguir un cambio realmente útil e innovador. Podríamos comenzar por no eliminar las asignaturas que mayor capacidad creativa desarrollan en los alumnos, tales como la música o la educación plástica, o incluir en toda las programaciones varias actividades el año que trabajen sobre esta habilidad.
También es importante despertar la capacidad crítica de los alumnos, pues habrá de ser críticos con el mundo que les rodea. Para ello podrían organizarse debates sobre un tema elegido por el alumnado, actual y polémico; analizando el contexto político, social y económico del asunto a tratar, viendo todos los puntos de vista. El profesor actúa como mero asesor y los alumnos desarrollan competencias lingüísticas, matemáticas, sobre las tics, aprender a aprender,… Además en un mundo globalizado parece útil y necesario que se fomente el respeto a la diversidad de opiniones y a crear tus propias creencias, no influenciadas por tu entorno, sino por ti mismo.
Es muy importante huir de la clase magistral y darle el protagonismo al alumno, pues es él quien debe trabajar en su propio proceso de aprendizaje. Fuera de las paredes del colegio no tendrá un guía que le diga cómo solucionar sus problemas o como alcanzar sus sueños. El alumno es responsable de su futuro y de salir airoso de los retos que en su vida se presenten. Por otro lado, está probado que los alumnos cuando explican alguna materia a sus compañeros consiguen interiorizar más los conocimientos y desarrollan múltiples competencias, entre ellas las interrelaciónales, algo muy importante teniendo en cuenta que estamos sumergidos en un mundo donde el ámbito social rodea cada actividad y cada momento de nuestra vida. Por todo ello la innovación propuesta en este caso es la integración, en el día a día de las aulas, del trabajo cooperativo, el cual se caracteriza precisamente por ser una metodología basada en una estructura cooperativa de incentivo, trabajo y motivaciones, lo que necesariamente implica crear una interdependencia positiva en la interacción alumno-alumno y alumno-profesor, en la evaluación individual y en el uso de habilidades interpersonales a la hora de actuar en pequeños grupos.
Otra innovación propuesta de los últimos años, para conseguir solucionar parte de la problemática del sistema educativo, es el concepto de la clase invertida. Esto significa que con el uso de las TICs las clases teóricas pasarían a formar parte de la tarea en casa y en clase se realizarían los ejercicios y la parte práctica de la asignatura. Y es que parece lógico que si hoy por hoy podemos encontrar cualquier información o dato en internet, nos enseñen en las aulas como utilizarlo y convertirlo en conocimiento útil para el desarrollo de nuestra vida.
Para finalizar con otra innovación, de las muchas ya nombradas que podría integrarse en el sistema educativo y que formaría al futuro de nuestro país, hagamos una reflexión dada la siguiente situación. No podremos entender un problema de matemáticas, si no hemos desarrollado anteriormente la capacidad lectora para comprenderlo, la cual debemos trabajar en la asignatura de lengua. En esta última nos enseña libros de literatura basada en la historia, que aprendemos en las asignaturas de sociales, dándole un mayor sentido a lo que relatan. Y mientras damos historia caemos en la conclusión que la evolución del mundo está íntimamente relacionada con la evaluación de la economía, cuyos datos son elaborados gracias a las matemáticas. Las asignaturas tanto hace 50 años como ahora, se imparten como si entre ellas no existiera ninguna relación, pero queda demostrado que si la tienen. Y esto era solo un ejemplo de los muchos que existen. Por ello una de las innovaciones más importantes a implantar es la metodología educativa basada en el aprendizaje por proyectos (PBL: Problem based learning). Esto se trata de un reto que los alumnos, trabajando cooperativamente y utilizando el conocimiento de todas las asignaturas, deben resolver trabajando con ello todas las competencias. Nada más cerca de la realidad a la que se enfrentas y se enfrentaran: pruebas que superar empleando las habilidades, destrezas y conocimientos adquiridos a lo largo de su vida.
Quedan en el aire cuestiones como el uso de juegos, incluso de videojuegos, en el aula para que las clases se conviertan en dinámicas y divertidas; o el planteamiento de tener aulas al aire libre que saquen a alumnos y profesores de las cuatro paredes en el que permanecen encerrados durante horas.
Todos estos son métodos estudiados y propuestos por muchos pedagogos y expertos en la materia; los cuales han trabajado durante años con alumnos de todas las edades y características, y que además están preocupados por crear un sistema educativo de calidad. Sin embargo estas innovaciones educativas no se llevan a la práctica en la mayoría de las ocasiones, ya sea porque los profesores no cuentan con la suficiente formación para aplicarlo, o porque el encorsetamiento y burocracia característica de nuestro sistema educativo no lo permite.
Por último, unas citas célebres de personajes influyentes que apoyan estas innovaciones en la educación.
“El objetivo principal de la educación es crear personas capaces de hacer cosas nuevas, y no simplemente repetir lo que otras generaciones hicieron” Jean Piaget.
“Sé que las aptitudes académicas son muy importantes, pero los sistemas escolares valoran mucho ciertos tipos de análisis y razonamientos críticos, en especial las palabras y los números. Por muy importante que sean estas aptitudes, la inteligencia humana es mucho más que eso” Ken Robinson.
“El pensamiento debería ser la asignatura más importante en los colegios” Edward Bono, creador del pensamiento lateral.
Compartir aprendizaje implica un razonamiento más elevado” David W. Johnson, pionero de la enseñanza cooperativa.
“Considero que el peor defecto de la educación es el sistema escolar que opera fundamentalmente a base del temor, la coacción y la autoridad artificial de los maestros” Albert Einstein.
Enviar comentario /
28 Nov 2016
por
jdiazsantiago
Sin categoría /
La economía colaborativa y el futuro del empleo

El trabajo es, y ha sido siempre, una parte fundamental de la vida de las personas. Es lo que nos permite llevar a cabo una gran parte de nuestros proyectos vitales, nos aporta independencia económica y nos permite realizarnos y progresar. No es mi intención entrar en disquisiciones históricas, políticas, ideológicas o filosóficas, pero es evidente que el trabajo ha sido también interpretado de formas muy distintas a lo largo de la historia, por las personas, grupos sociales y civilizaciones.
Desde la existencia de la esclavitud en la antigua Grecia y durante el imperio romano, pasando por el “ora et labora” de los monasterios cristianos, y llegando a la revolución industrial, con sus luces y sus sombras, muchas de las reflexiones, preocupaciones, avances y conflictos de la humanidad han tenido en el trabajo uno de sus puntos centrales.
Pues bien, actualmente nos encontramos en un momento histórico en el que se están produciendo una gran cantidad de cambios, equiparables, dadas sus dimensiones e impacto, a aquellos cambios que se produjeron entre los siglos XVIII y XIX y que hoy llamamos Revolución Industrial.
Economía Colaborativa
Todos estos cambios se están produciendo poco a poco, delante de nuestros ojos, de forma que apenas nos damos cuenta. Pero si comparamos el momento actual con el de hace 10 o incluso 5 años, nos damos cuenta de que muchas cosas han cambiado y otras, ni siquiera existían entonces. Tener “un simple” teléfono móvil, conectado a internet, y que en unos cuantos toques nos permite hacer la compra online y que Amazon nos la sirva en 2 horas en casa. O que, a la hora de irnos de vacaciones, compartamos coche usando BlaBlaCar, y alquilemos una casa con Airbnb. O que vayamos al aeropuerto en un coche de Uber ó Cabify.
Estas empresas innovadoras son las que están creando la economía colaborativa. El verdadero impacto que tienen estas plataformas es que, sin contar con flotas de coches, o cadenas de hoteles, actúan como intermediarios entre los individuos que tienen interés en bienes o servicios. Es decir, hacen posible el modelo “peer to peer”. Alguien con carnet de conducir y un coche de gama media-alta puede dedicar una serie de horas a la semana a ser conductor de Uber. O alguien interesado en generar un ingreso extra, puede alquilar su casa, o parte de ella, a través de Airbnb. Y así un largo etcétera.
Esto abre un amplio abanico de posibilidades, ya que prácticamente cualquiera puede realizar este tipo de trabajos, compatibilizándolo con otras ocupaciones, y sin necesidad de que sean un trabajo fijo.
Lógicamente, esta nueva economía colaborativa tiene un grandísimo impacto en sectores regulados, en los que la entrada de competidores era, hasta hace poco, muy difícil. Por ejemplo, en el sector del taxi, o en el sector hotelero.
Otras plataformas como Upwork ó Fiverr, hacen más fácil un modelo de trabajo «freelance», que cada vez va a ser más común.
Automatización

Otro de los grandes cambios que ya se está produciendo, y que va a afectar de forma definitiva a muchos trabajos, es la automatización derivada de la Inteligencia Artificial. Mucho se ha escrito sobre si algún día las máquinas igualarán a las personas en cuanto a su capacidad de pensar por sí mismas (lo que se conoce como la singularidad). No voy a entrar en ese aspecto más filosófico, pero sí me gustaría resaltar algunos aspectos prácticos que en el futuro cercano van a tener un impacto importante en el trabajo tal y como lo conocemos.
Durante las últimas décadas, se ha venido produciendo una automatización de las tareas más tediosas. Tareas monótonas, que no requerían “pensar”, se han ido delegando tradicionalmente en máquinas. Por lo tanto, los trabajadores menos cualificados o cuyos trabajos eran más manuales y repetitivos (lo que en inglés se denominan “blue collars”), han sido los que más se han visto tradicionalmente afectados por esta automatización.
Pero no es (sólo) esta automatización de la que estamos hablando. Actualmente, gracias a los avances en la IA, se están empezando a automatizar tareas que sí requieren de cierta actividad cognitiva, ya sea ésta interactuando con el entorno, o aprendiendo a mejorar la técnica. Un ejemplo simple sería un robot aspirador en el hogar, que es capaz de sortear obstáculos, y de aprender las rutas más óptimas, adaptándose a la forma de nuestra casa. Pero los ejemplos podrían seguir en campos como la contabilidad, vigilancia y seguridad, conducción de vehículos o incluso diagnóstico médico. Es decir, también los trabajos más cualificados (los realizados por “white collars”) son susceptibles de ser realizados por máquinas.
Además, en ciertas tareas, como reconocimiento de imágenes (describir qué hay en una foto), las máquinas ya han igualado a las personas. Éste, y otros avances, sobre todo impulsados por los recientes desarrollos del “Deep Learning” abren un amplio abanico de posibles funcionalidades, como por ejemplo, que un automóvil se conduzca sólo, y además lo haga de forma más segura y con menos accidentes. Todos los coches que a día de hoy fabrica Tesla, llevan ya incorporada esta tecnología.
Futuro del Empleo
Ante esta perspectiva de cambios, cabe preguntarse qué va a ocurrir con todas las personas cuyos trabajos actuales van a desaparecer. La respuesta a esta pregunta no está clara. Hay una división (aproximadamente al 50% – 50%) entre los optimistas, que piensan que, aunque desaparecerán puestos de trabajo, se crearán otros nuevos, y los más pesimistas que afirman que ésta nueva situación sólo ayudará a que crezcan las desigualdades y que mucha gente se suma en la pobreza.
Mi opinión es moderadamente optimista. No creo que vayamos a llegar en pocos años a una situación apocalíptica, en la que millones de personas hayan sido despojadas de sus empleos, aumenten aún más las desigualdades y la delincuencia y la conflictividad social se disparen. Pero sí creo que hay cosas que han cambiado para siempre. Cada vez será menos comunes los trabajos fijos y que duran “toda la vida”. El trabajo en remoto y los contratos de “freelance” aumentarán significativamente. Será necesario tener una actitud de estar aprendiendo y formándose continuamente, ya sea a través de internet (a través de MOOCS) o de formación superior.
En cualquier caso, en mi opinión, hay aspectos en los que las máquinas nunca podrán sustituir completamente a una persona. Por ejemplo, el impacto positivo y duradero que un buen profesor puede tener en un estudiante, difícilmente puede ser igualado por un sistema de Inteligencia Artificial. Lo cual no quiere decir, que tendremos que aprender a adaptarnos a un entorno laboral en el que, cada vez más, habrá tareas que serán realizadas por máquinas.
Enviar comentario /
27 Nov 2016
por
falba
Sin categoría /
PERDER EL TREN DE LA INNOVACION
Hace un par de días leí en un recorte de prensa que la inversión en España en I+D+I sigue cayendo a pesar de las recuperación económica. Una de las personas que intervenían en el debate afirmaba que en España seguirá dependiendo del turismo de sol y playa y del ladrillo, y que la inversión en ciencia e innovación prologara su caída año tras año. Según los datos actuales, perderemos el tren en el que están subidos Alemania, Japón, Corea y Estados Unidos.
Todos los partidos políticos insisten en que hay que cambiar el modelo actual y hay una necesidad de que exista más y mejor I+D+i, pero a día de hoy ninguno lo ha llevado a cabo, siendo el único país junto con Portugal, que acumula una caída del gasto público y privado en este ámbito, según la Fundación Cotec para la innovación.
Tras este desolador panorama, algunos expertos proponen algunas propuestas para convertir a España en uno país científico e innovador:
- Más inversión pública y privada
En el 2014, el PIB creció un 1.4 % mientras que el gasto en investigación cayó un 1.5%. En esta batalla que mantenemos para no descolgarnos de los países innovadores, hemos perdido 10 años de un plumazo, comparándonos con nuestros vecinos europeos. El principal problema es que como todos sabemos, la investigación pública es siempre la primera víctima cuando aprieta la crisis, debido a que los políticos no ven ni la ciencia o la innovación como el motor del progreso y el bienestar. Los recortes en inversión pública siempre han estado relacionado con un déficit en la inversión privada. Según datos bibliográficos, en 2014, el número de empresas que declaraban invertir en innovación fueron meo de la mitad de la que lo hacían en el 2008
- Más transparencia.
España necesita elaborar un plan de negocio donde se deje claro a donde queremos llegar a medio y largo plazo y que necesitaremos para conseguirlo. Para ello se necesitara generar una fiscalidad más favorable (mediante créditos, subvenciones, deducciones), eliminación de regulaciones que han quedado antiguas, coordinación entre las distintas administraciones del estado o una mejora de la seguridad jurídica para las multinacionales que quieran innovar en España.
Los investigadores reclaman una mayor autonomía de los centros de investigación, las universidades y los organismos públicos de investigación. Además piden que se les dote de direcciones científicas independientes del ciclo político que puedan tomar sus propias decisiones sin ser coaccionadas. Otra idea es que se mejore el proceso de evaluación donde los científicos pierden un tiempo enorme rellenando papeles en vez de investigar en los laboratorios.
- Educación innovadora
En este punto casi todos estamos de acuerdo en que la educación debe cambiar, de una forma revolucionaria, radical y profunda. Ante la futura automatización del trabajo donde como alguno de mis compañeros y han hecho referencia, en el sentido de que los robots remplazaran a los obreros, debemos buscar los puntos clave donde las maquinas no puedan superarnos.
Será necesario la formación de las personas con el objetivo de conseguir trabajadores empáticos, creativos, innovadores y preparados para el cambio. En la actualidad estamos viendo como la colaboración entre entidades públicas y privadas son el día a día, por lo que tendremos que aprender a colaborar y a trabajar en proyectos conformados por grupos empresariales.
- Innovación como base
La innovación es importante en todas las etapas del desarrollo, pero diferentes tipos de innovación juegan diferentes roles en cada una de éstas. En las etapas iniciales, la innovación incremental se asocia con la adopción de tecnología extranjera y la innovación social puede mejorar la efectividad de los negocios y servicios públicos. En etapas posteriores, la innovación se basa, mayoritariamente, en alta tecnología y en Investigación y Desarrollo (I+D) y va enfocada a factores de competitividad y aprendizaje.
La innovación necesita ser llevada a cabo de una manera sistemática. Ello requiere un método que estructure y ordene todas las acciones necesarias. Es por ello que deberían seguirse unos principios o pautas que nos permitan de alguna manera ordenar los pasos a dar para llevar a cabo nuestra actividad innovadora.
Se trata de valorar la información que está digitalizada, las bases de datos, los conocimientos, los procesos, la formación, el talento, la creatividad… “Más de la mitad del valor de la economía global ya es intangible”, explica Barrero. “Las grandes entidades financian proyectos que pueden medir, pero es urgente que aprendan a medir lo que no se puede tocar”.
Señores políticos, escuchen esta serie de propuestas y no dejen que perdamos el tren de la innovación para siempre
Enviar comentario /
27 Nov 2016
por
pcabezas
Sin categoría /
Innovación en el puesto de trabajo
Me gustaría reflexionar sobre cómo los distintos gobiernos podrían atreverse a innovar en lo relacionado con el entorno laboral. Cuando se habla de reformas laborales, pocas veces se pone el foco en aquello que podría hacer un poco más feliz al trabajador. Un trabajador feliz, sin duda, aumenta la productividad.
Escribo desde una pequeña habitación del piso en el que vivo, donde tengo mi escritorio, con una pequeña lámpara de luz cálida. Estoy frente a la ventana, fuera llueve a mares y hace frío. El silencio es casi absoluto, a veces solo interrumpido por ese agua que no deja de caer. He pasado la tarde trabajando en algunos proyectos personales y la verdad es que las horas me cundieron mucho. ¿Podría esta habitación o la terraza de mi casa ser mi puesto de trabajo?

Ya hoy existen muchas empresas que son bastante flexibles en cuanto a una hora de entrada o salida, trabajar desde casa o incluso reducir la jornada sin que lo haga la productividad. Sin embargo estaremos de acuerdo que no es la norma, sino la excepción.
¿Qué pasaría si en una de esas reformas laborales un gobierno se atreviera a incentivar ciertos hábitos de las empresas y sus trabajadores?
Imaginemos que tenemos puestos de trabajos divididos según la necesidad de ejercerlo en forma presencial. Podríamos tener trabajo de tres tipos: A, B y C.
- Trabajos tipo A: Necesitan ejercer el 100% de las horas de forma presencial.
- Trabajos tipo B: Solo necesitan un 40-60% de las horas de forma presencial.
- Trabajos tipo C: Solo necesitan un 10-20% de las horas de forma presencial.
Hoy día, hay cantidad de gente que se desplaza a un lugar concreto, causando atascos, descansando menos, consumiendo energía, contaminando…para hacer algo que podría haber hecho sin problema alguno desde casa. ¿Interesaría a un estado incentivar de algún modo a las empresas según el tipo de trabajador que éstas tengan?
Muchas de las carreteras que se han quedado obsoletas y son causa de insufribles atascos, realmente solo se ven desbordadas en esas horas puntas de entrada y salida de los puestos de trabajo. ¿Ahorraría dinero el estado con menos coches en las carreteras? ¿Notaríamos una mejora de los niveles de contaminación?

Claro está, que unido a alguna iniciativa de este tipo tendrían que ir iniciativas internas a las empresas que fuesen capaces de mostrar que con las herramientas adecuadas y procesos internos bien definidos, el trabajo colaborativo en la distancia puede llegar a ser incluso más eficiente y productivo que esas infinitas horas de oficina.
Aunque esto no es más que una pequeña reflexión y la puerta a un posible debate, siento curiosidad por qué impacto podría tener una medida de este tipo, en la que las empresas pagasen más o menos impuestos por cada trabajador según este sea A, B o C. En primer lugar, estaría interesante ver qué porcentaje de los actuales trabajadores en nuestro país son de tipo A, B o C ¿Harían un esfuerzo aquellas empresas con alto índice de trabajadores tipo C en descentralizar su negocio e implementar nuevas herramientas y procesos de comunicación interna? ¿Sería algo aceptado por todos los trabajadores o nos encontraríamos con aquellos que prefieren ir a diario a la oficina? ¿Ayudaría a la conciliación?
En líneas generales,más allá de esta alternativa, lo que me gustaría transmitir es que nuestros políticos realmente están en una posición desde la que pueden transformar nuestra sociedad innovando. Nosotros, miembros de esta sociedad, pasamos casi un tercio de nuestra vida trabajando o intentando trabajar para tener una vida digna. Por suerte o desgracia, nuestra vida parece girar en torno al trabajo y aunque ignoro cuáles son una a una las iniciativas que puede llevar un gobierno para incentivar y mejorar el empleo, me da la sensación que estas siguen siendo poco innovadoras, arriesgadas y creativas.
Estoy convencido, que si ponemos este tema sobre la mesa y abrimos un debate o sesión de brainstorming con profesionales de diversa índole, saldrían muchísimas ideas y cosas que mejorar en nuestro actual entorno laboral. Pero lo cierto es, que cuesta mucho romper con lo preestablecido. Hemos avanzamos mucho como sociedad y tecnológicamente, pero hablar de menos de 40 horas, que luego son 50 o 60 o de ciertas alternativas en cuanto a horarios y formas de trabajar, es algo que no termina de encajar. En definitiva, mientras estas iniciativas no vengan impuestas/reguladas por la ley, las empresas seguirán tratando de hacer negocios de la mejor forma que saben, igual sin saber que probablemente cambiando algo que se viene haciendo de la misma manera durante los últimos 40 años, puede que les ofrezca más y mejores oportunidades de negocio, teniendo en cuenta, insisto, lo que hemos cambiando en este tiempo.
Se llama, adaptación al cambio.
Enviar comentario /
27 Nov 2016
por
mromeroromero
Sin categoría /
¿ Se puede innovar en la justicia?
La justicia, divina palabra, (del latín iustitĭa), que, a su vez, viene de ius — derecho — y significa en su acepción propia «lo justo». Si lo buscamos en la RAE, institución utilizada por todos diariamente, «Principio moral que lleva a dar a cada uno lo que le corresponde o pertenece».

Si nos dejamos de definiciones, clásicas y políticamente correctas, y nos centramos en el ámbito de utilización en el cual nos basamos la gran mayoría de los ciudadanos, la justicia es el conjunto de pautas y criterios que establecen un marco adecuado para las relaciones entre personas e instituciones, autorizando, prohibiendo y permitiendo acciones específicas en la interacción de individuos e instituciones. ¿ Complicado, verdad?. Pues en España, país de tradiciones muy tradicionales y por supuesto de « españoles y muchos españoles», cita de un gran presidente, el funcionamiento de su administración por lo tanto, también lo es. Me refería a lo de complicado.
En los años de bonanza, cada Comunidad implantó sistemas y aplicaciones diferentes para la modernización de la Administración, sin tener un consenso unas con otras. Hoy en día, esto supone una descoordinación e incompatibilidad entre las diferentes comunidades que impiden del desarrollo conjunto de la “e-justicia”.
Por ello, existe una necesidad de aunar procesos y soluciones para impulsar el expediente electrónico judicial, la firma electrónica… En definitiva, la integración de la Administración de Justicia en el mundo digital eligiendo para ello las mejores soluciones y la externalización de las mismas en proveedores líderes en el mercado y en el sector público. Es un paso fundamental que hay que dar para implantar, desarrollar y unificar todas las soluciones que ayuden al ahorro de costes y tiempos y optimización de los recursos y esfuerzos para mejorar la operatividad.
¿ Pero acaso, esto interesa?, una noticia muy mediática ha sido la muerte inesperada de Rita Barberá, que en paz descanse, senadora por el grupo mixto y cabeza visible del PP durante toda su historia.

Si analizamos el caso, Barberá compareció el martes 15 de marzo 2016 ante los medios de comunicación un día después de que el instructor del caso Taula le ofreciera declarar voluntariamente en sede judicial para anunciar que aceptaba el ofrecimiento del magistrado. El 20 de octubre el Tribunal Supremo le citó para que declarase como imputada por blanqueo, declarando el 21 de noviembre del mismo año. Sin embargo, no pudo ser juzgada, ya que dos días después de declarar en el Supremo falleció tras sufrir un infarto en un céntrico hotel de la capital madrileña, a donde se había trasladado para acudir al pleno del Senado por blanqueo de capitales. ¿ 8 meses para declarar?, he aquí mi interés por poner en punto de mira sobre lo lenta que actúa la administración.
Un ejemplo de buen hacer puede ser el de la administración de Cataluña. Actualmente, el 99% de la documentación judicial de entrada a la administración de Justicia se gesta en formato electrónico. La Generalitat de Catalunya contó con la experiencia de T-Systems para introducir una serie de módulos en el sistema de información e-Justicia.cat para la presentación telemática de demandas y escritos de la jurisdicción civil. De esta manera, ha sido posible agilizar los procesos de entrada de asuntos, mejorar la calidad de los datos y aumentar la seguridad durante todo el proceso. Por ahora, los usuarios de este módulo son los procuradores, pero está previsto ampliarlo a abogados y graduados sociales a corto plazo.
Sin embargo, no hay siempre que apoyarse en el aspecto tecnológico. Por ejemplo la Justicia en Estados Unidos es más efectiva que en España, en cuanto que es más rápida, lo que no necesariamente quiere decir que sea más justa. Por el pragmatismo propio de la idiosincrasia del país, muchos casos se resuelven con compensaciones económicas antes de llegar a juicio, especialmente en la vía civil, pero también ocurre en procesos criminales.

Esa práctica contagia agilidad al resto del sistema, de forma que en situaciones de urgencia pública, como fue el caso de estafa millonaria de Bernard Madoff, en medio de la crisis financiera, existe un compromiso de Ministerio Público y judicatura de acelerar los procedimientos. Después de que estallara el escándalo de su estafa piramidal y se realizaran investigaciones, Madoff fue acusado formalmente y detenido el 11 diciembre de 2008. Solo unos meses después ya tenía sentencia firme: el 29 de junio de 2009 recibió una condena de 150 años de prisión.
Por lo tanto, soluciones innovadoras hay, desde la tecnología al pragmatismo, simplemente hay que enfocar el problema de una manera un poco menos interesada. Así que como dice el refrán «A buen entendedor, pocas palabras bastan».
Juan Manuel Fernández.
2 comentarios /
27 Nov 2016
por
jfernandezsanchez
Sin categoría /
.png)
].gif)
].png)
].png)
].png)
].png)
].png)
